Welcome to our in-depth Linux operating system architecture overview. This guide is crafted for Linux enthusiasts and IT professionals seeking a clear understanding of how Linux functions behind the scenes.
Understanding the design of Linux can be beneficial for several reasons: pure interest, learning about OS design principles, contributing to Linux kernel development, or gaining inspiration for creating a new system. This guide primarily focuses on the first two objectives, offering a comprehensive overview of the Linux operating system architecture for beginners.
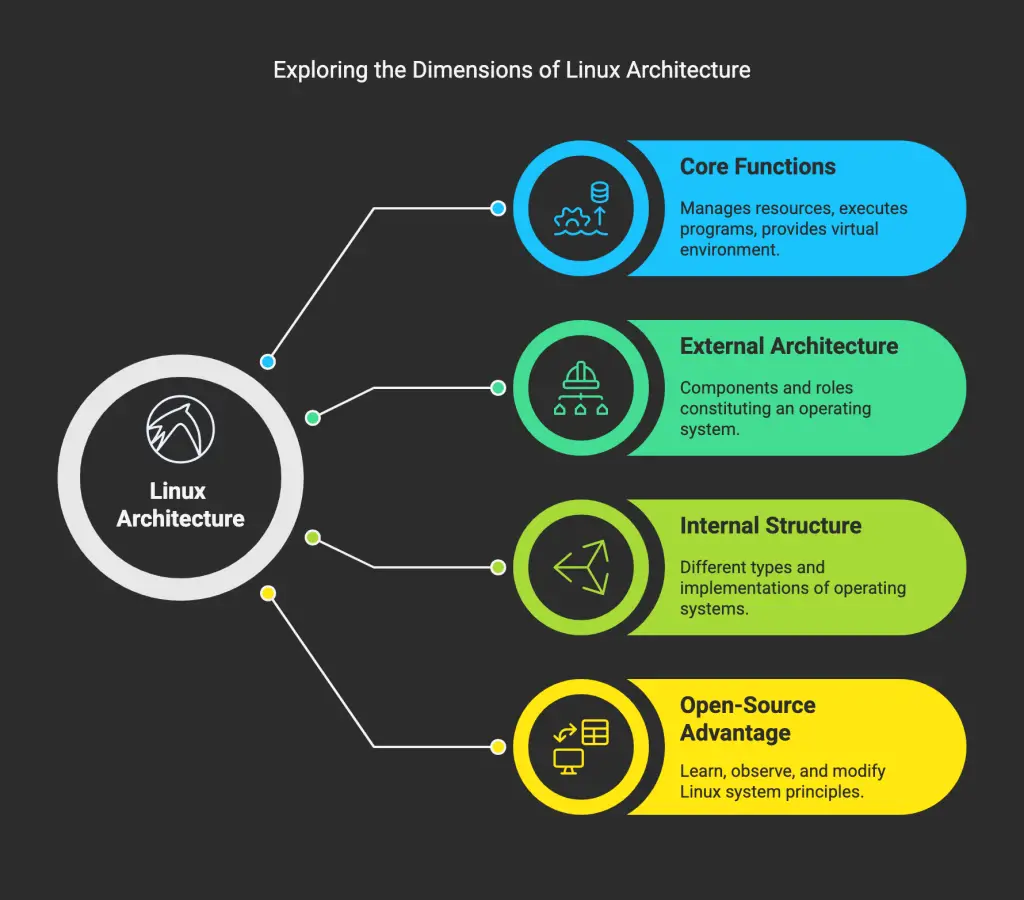
Operating systems are fundamental to the operation of our computers. They manage system resources, execute programs, and provide a virtual environment for all our computing tasks. This article will cover the three core functions of operating systems and their defining characteristics. We’ll examine the external architecture, including the various components that constitute an operating system and their roles. We’ll also delve into the internal structure of operating systems, exploring different types and their implementations. Whether you’re a technology enthusiast or simply curious about the underlying mechanisms that power your Linux system, this guide will provide a clearer understanding of Linux kernel architecture.
A significant advantage of Linux-based operating systems is their open-source nature. This allows you to not only learn about the system’s core principles but also observe how its features are implemented and even modify them. This is particularly useful if you’re interested in learning how the Linux kernel manages processes and memory.
Read: Differences between a thread and a process
1. The Three Primary Functions of an Operating System
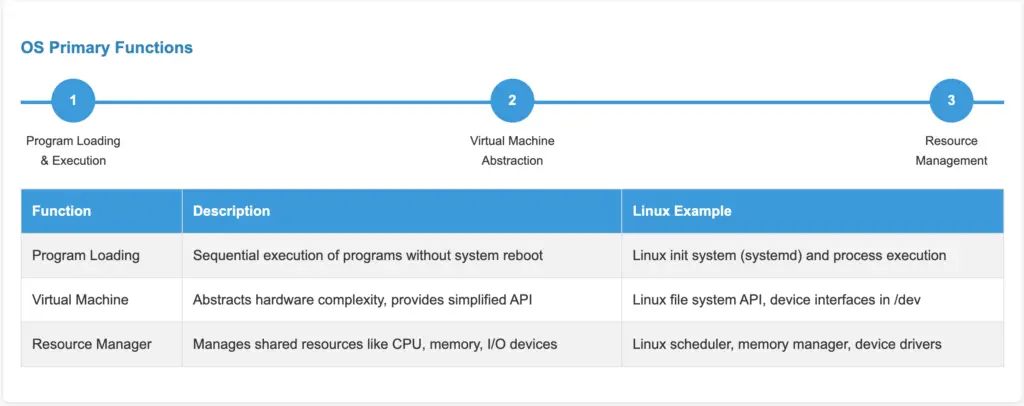
In essence, an operating system performs three key tasks: it sequentially executes programs, establishes a virtual environment, and manages system resources. Let’s examine each of these functions, explaining how an operating system handles program execution and resource allocation.
1.1 Program Loading: Early Boot Sequences in Linux
Historically, microcomputers didn’t include an operating system. Early models often featured a single program – a BASIC language interpreter stored in ROM. However, with the advent of cassette players and subsequently floppy drives, this began to evolve. Users could insert a floppy disk containing a different program, and it would run. If no floppy disk was present, the BASIC interpreter would be loaded. This illustrates the very earliest form of boot sequence and program execution on personal computers.

Early boot sequence in Linux
For instance, the Apple II required a system restart each time a user wanted to switch programs. The introduction of operating systems, stored on floppy disks or RAM, simplified this process. These OSs would present a prompt on the screen. Users could then replace the boot disk with a disk containing the desired program, type the program’s name at the command line, and press enter. This enabled the execution of multiple programs sequentially without requiring a system reboot. For example, a user could write a document in a word processor and then run a separate program to print it. This demonstrates early operating systems facilitating sequential program execution.
Read: Understanding Linux File Permissions: The Complete Guide to Securing Your System Files
1.2 The Operating System as a Virtual Machine
Directly managing a computer system like the IBM-PC using machine language is complex, particularly for input/output operations. If every programmer had to understand the intricacies of hard drive operation and potential errors during block reads, program development would be significantly hindered. To address this, a software layer was introduced to abstract the hardware complexities for programmers, providing them with a more user-friendly API. This is a key concept in understanding how operating systems provide an abstraction layer for hardware interaction.
Consider programming the I/O for a hard drive on an IBM-PC using an IDE controller. This is an example of low-level hardware interaction before operating system abstraction.
The IDE controller utilizes eight primary commands, which involve loading one to five bytes into its registers. These commands handle tasks such as reading and writing data, moving the drive arm, formatting the drive, initialization, testing, restoration, and controller/drive recalibration.
The key commands, read and write, each require seven parameters grouped into six bytes. These parameters specify details like the sector to read or write, the number of sectors to process, and error correction settings. Upon completion of the operation, the controller returns fourteen status and error fields, grouped into seven bytes. This illustrates the complexity that operating systems hide from application developers.
Most programmers prefer to avoid the low-level technicalities of hard drive programming. They require a simplified, high-level interface. For instance, they want to interact with the disk as a collection of named files, with the ability to open a file for reading or writing, perform read/write operations, and then close the file. The virtual machine component of an operating system abstracts the hardware from the programmer, presenting a simplified view of named files that can be accessed for reading and writing. This is fundamental to understanding how file systems are presented to users and applications in Linux.
Read: How to View Linux Software and Hardware Info in the Terminal
1.3 The Operating System as a Resource Manager
Modern computers incorporate various components, including processors, memory, clocks, disks, monitors, network interfaces, printers, and other peripherals, which can be accessed concurrently by multiple users. The operating system acts as a central manager, ensuring that all programs requesting access to processors, memory, and peripherals receive a fair allocation. This resource management is critical for system stability and performance.
Imagine the chaos if three programs attempted to print simultaneously to the same printer. The output would be a jumbled mix of lines from each program. The operating system prevents this by buffering print results to a file on the disk. Once printing is complete, the operating system can process the buffer and print each file sequentially. Meanwhile, other programs can continue executing and generating output, unaware that their output is not yet being sent directly to the printer. This demonstrates how the operating system manages shared resources like printers.
Read: Mastering Linux Repository Updates: The Essential Guide for Secure and Optimized Package Management
2. Characteristics of an Operating System
2.1 Multitasking Systems: Processes, Timesharing, and Abstraction
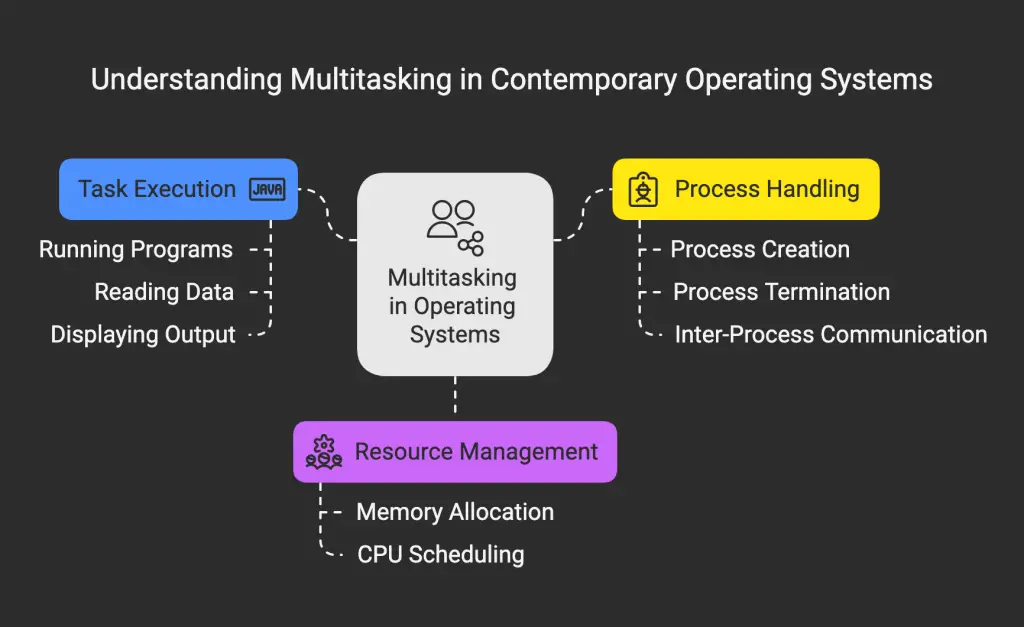
Contemporary operating systems allow for the simultaneous execution of multiple tasks, such as running a program while reading data from a disk or displaying output on a terminal or printer. This capability is referred to as multitasking or a multi-programmed operating system. Understanding multitasking is crucial for grasping how Linux handles multiple processes concurrently.
Processes
The core concept of multitasking operating systems is the process, not just the program. A single program can be running multiple times concurrently, such as having two windows open with the “emacs” or “gv” text editor for text comparison. Each instance of a running program is a separate process in Linux.
A process represents a specific instance of a program in execution. It encompasses not only the program code but also the associated data and all information necessary to resume execution if interrupted (e.g., execution stack, program counter). This is referred to as the program’s execution environment. The process descriptor stores all the information about a running process.
In Linux, a process is often termed a “task.”
Read: Processes in Linux – Guide for beginners
Timesharing
Most multitasking operating systems are designed to run on computers with a single microprocessor. While the processor can only execute one instruction at a time, the system can rapidly switch between programs in milliseconds, creating the illusion of simultaneous execution. This is known as a time-sharing system. Time-sharing allows multiple users and processes to share a single CPU.
This rapid switching of the processor between programs is sometimes called “pseudo-parallelism” to distinguish it from true parallelism, where the processor and certain I/O devices operate concurrently. True parallelism is achieved through hardware.
Read: The Ultimate Guide to Viewing and Analyzing Core Dump Files on Ubuntu
Abstraction of the Process
It’s useful to conceptualize each process as having its own virtual processor, even though the physical processor is switching between multiple processes. This makes it easier to understand the system as a collection of processes running in parallel, rather than the processor being divided among different processes. This rapid switching is known as multi-programming. Process abstraction simplifies the programmer’s view of the system.
The graph below illustrates four processes running concurrently. The main graph is a simplified representation. Each of the four programs becomes a separate process with its own control flow (and program counter). The last graph shows that over a period of time, all processes make progress, but at any given instant, only one is active. This demonstrates how the Linux scheduler manages process execution over time.
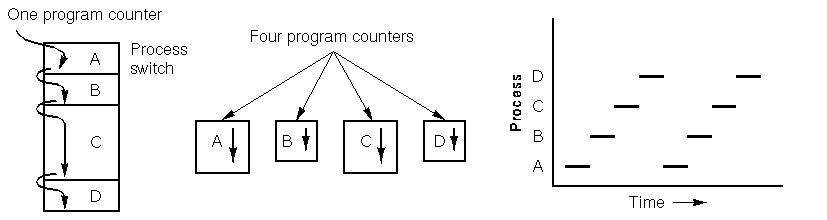
Read: Demystifying Linux Devices and Modules: A Practical Guide for Admins
Environment Variables
A process encompasses more than just the program itself; it includes all associated environment variables. This includes details like the files it’s accessing and the current value of the program counter. This is important because two processes can share the same code but have different files and program counter values. Additionally, due to multitasking, the operating system may need to interrupt a process to execute another. When this occurs, the process’s information must be saved to allow it to resume seamlessly later. The specific environment variables required depend on the operating system and its version. This information is stored in the process descriptor. Environment variables define the context in which a process runs in Linux.
Read: How is the path environment variable managed in Linux/Ubuntu/Debian?
Memory Space of a Process
Many operating systems allocate a dedicated memory space to each process, separate from other processes. This is referred to as the process’s address space. Each process in Linux has its own isolated memory space.
Impact on the Processing of Durations
Because the processor switches between processes, the execution speed of a process is not constant and may vary if the same process is run repeatedly. Therefore, processes should not rely on specific time frames. This is a key consideration when designing real-time applications on a time-sharing operating system.
Consider a floppy disk drive I/O process. It activates the drive’s motor, executes a loop 1000 times to allow the floppy to stabilize its speed, and then requests to read the first record. However, if the processor was occupied with another process during the loop, the I/O process might resume too late, after the read head has already missed the first record. This demonstrates how context switching can affect the timing of I/O operations.
In scenarios where a process requires precise timing, such as events that must occur after a few milliseconds, additional measures are necessary. Timers are often used for this purpose, as discussed later in this article. Timers and scheduling policies are used to manage time-critical processes in Linux.
However, in most cases, processes are not affected by the processor’s switching and the varying execution speeds between processes.
2.2 Multi-user Systems
A multi-user system allows multiple users to run their applications concurrently without interfering with each other. “Concurrent” implies that applications can run simultaneously, competing for access to resources like the processor, memory, and hard drives. “Independent” means that each application can operate without being affected by the actions of other users’ applications. Linux is designed as a multi-user operating system from the ground up.
A system being multi-user does not necessarily imply that it is also multi-tasking. For example, MS-DOS is a single-user, single-task system, while MacOS 6.1 and Windows 3.1 are single-user but multi-tasking. Unix and Windows NT are both multi-user and multi-tasking. This distinction is important for understanding the capabilities of different operating systems.
How it Works
Multi-user systems operate by allocating time slots to each user. However, switching between applications can introduce delays and affect the perceived speed experienced by users. This is an inherent characteristic of such systems. The scheduler plays a crucial role in managing user access to resources.
Associated Mechanisms
Multi-user operating systems require several key mechanisms:
Firstly, an authentication process is necessary to verify user identities. Secondly, protection mechanisms are needed to prevent malicious programs – either accidental ones that might disrupt other applications or intentionally harmful ones that could compromise other users or their data. User authentication and access control are essential security features in Linux.
Finally, an accounting system is required to track resource usage by each user.
Read: Top 11 Linux Log Monitoring Tools for System Administrators
Users
In a multi-user system, each user has a private area within the system, such as dedicated disk space for files and personal emails. The operating system ensures the privacy of each user’s data, preventing unauthorized access. The system also prevents users from using the system to intrude on other users’ private spaces. File permissions and ownership are crucial for maintaining user privacy in Linux.
Each user has a unique identifier, known as the User ID (UID), and typically only authorized individuals are granted access to the system. When a user initiates a session, the operating system prompts for a username and password. If the provided information is incorrect, access is denied. Understanding user accounts and authentication is fundamental to Linux system administration.
Read: How to create a Sudo user on Ubuntu
User Groups
In a multi-user environment, users can belong to one or more groups to facilitate sharing. A group is identified by a unique number, known as the Group ID (GID). For example, a file is associated with a single group, and in Unix, access can be restricted to the owner, the group, or others. User groups simplify file and resource sharing in Linux.
Superuser
A multi-user operating system also includes a special user called the superuser or administrator. This user must log in as the superuser to manage other users and perform system maintenance tasks, such as backups and software updates. The superuser possesses elevated privileges and can perform most actions, except for accessing certain I/O ports not provided by the kernel. Protection mechanisms do not apply to the superuser. The root user has complete control over the system in Linux.
Read: How to fix high memory usage in Linux
3. External Architecture of an Operating System
3.1 Kernel and Utilities
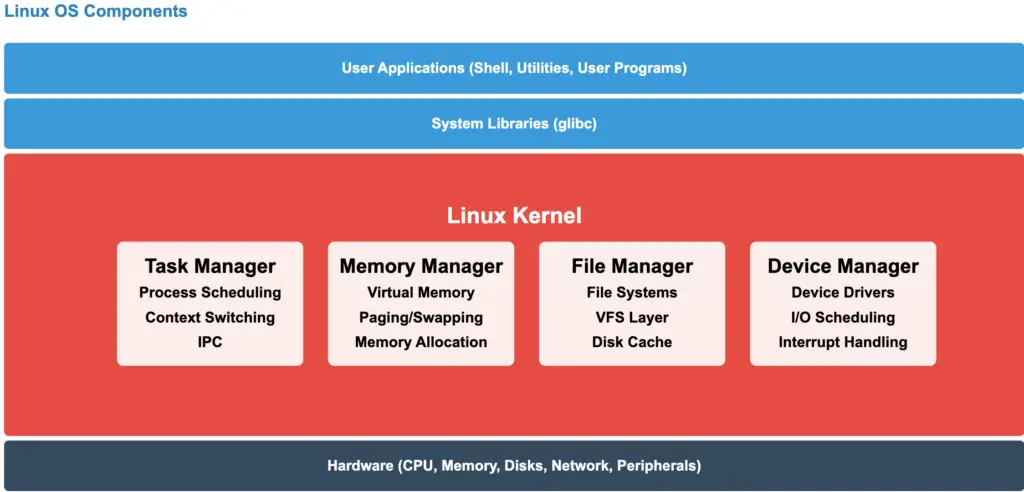
The operating system comprises numerous routines, with the most critical ones forming the kernel. The kernel is loaded into the computer’s memory during system startup and contains the essential procedures for system operation. The remaining, less critical routines are known as utilities. The Linux kernel is the core of the operating system, managing all system resources.
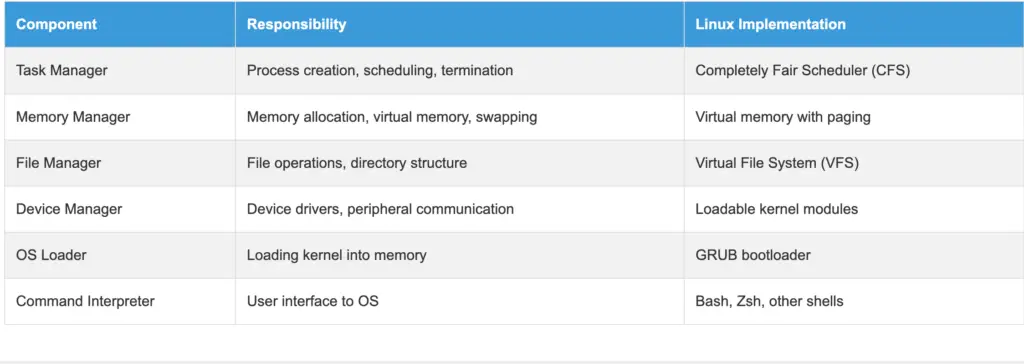
The kernel of an operating system typically consists of four main components: the task manager (or process manager), the memory manager, the file manager, and the I/O device manager. It also includes two auxiliary components: the operating system loader and the command interpreter. These components work together to provide a complete operating environment.
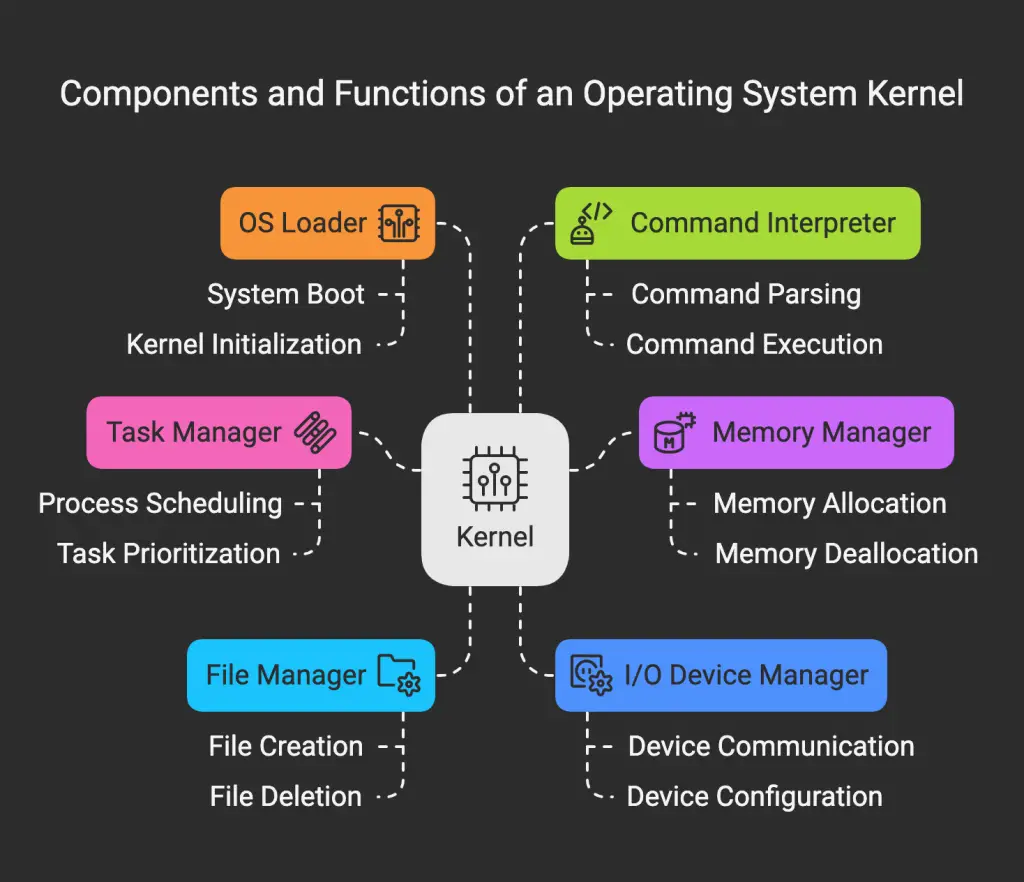
3.2 The Task Manager
In a timesharing system, the task manager (or scheduler) is a crucial component. It allocates processor time in a single-processor system. Periodically, the task manager decides to suspend the currently executing process and initiate another, either because the current process has exhausted its allocated time or is awaiting data from a peripheral. The task manager, or scheduler, determines which process runs and when.
Managing concurrent activities can be complex, so operating system designers have continuously refined the handling of parallel operations over time. Different scheduling algorithms are used to optimize system performance.
Some operating systems only allow the execution of processes that cannot be interrupted by the task manager, meaning the task manager only intervenes when a process voluntarily relinquishes control. However, in a multi-user system, processes must be interruptible to allow the task manager to control them. Preemptive multitasking allows the operating system to interrupt processes.
Read: Guide to Linux Ubuntu/Debian log files for beginners
3.3 The Memory Manager
Memory is a valuable resource that requires careful management. By the late 1980s, even small computers had significantly more memory than the IBM 7094, a powerful computer of the early 1960s. However, program sizes have increased proportionally with memory capacities. The memory manager is responsible for allocating and deallocating memory to processes.
The memory manager is responsible for tracking memory usage. It monitors which memory regions are occupied and which are free, allocates memory to processes as needed, reclaims memory when a process terminates, and manages data transfer (swapping or paging) between main memory and disk when main memory cannot accommodate all processes. Virtual memory allows processes to use more memory than is physically available.
3.4 The File Manager
As previously mentioned, a key function of the operating system is to abstract the complexities of disks and other I/O devices, providing programmers with a simplified model. This is achieved through the concept of a file. The file manager provides a hierarchical structure for organizing files and directories.
3.5 The Device Manager
Managing computer input and output (I/O) devices is a primary responsibility of an operating system. It sends commands to peripherals, handles interruptions, and manages any errors that may occur. The operating system should also provide a user-friendly interface between peripherals and the rest of the system, regardless of the specific peripheral being used. I/O code constitutes a significant portion of the operating system. Device drivers allow the operating system to communicate with hardware devices.
Many operating systems incorporate a layer of abstraction that allows users to perform I/O operations without dealing with hardware specifics. This abstraction represents each device as a special file, allowing I/O devices to be treated like files. Unix is an example of an operating system that implements this approach. Device files in /dev provide access to hardware devices in Linux.
Read: Task scheduling on Linux: CRONTAB
3.6 The Operating System Loader
The operating system loader and the command interpreter are essential components of a computer’s operating system. When a computer is powered on, the BIOS software is loaded into RAM and initializes the devices. The OS pre-loader then takes over and loads the operating system onto the computer. The design of the loader and pre-loader is crucial, even though they are not technically part of the OS. The bootloader is responsible for loading the kernel into memory.
3.7 The Command Interpreter
The command interpreter, often called a shell, is typically considered part of the operating system, unlike system programs such as text editors and compilers. The command interpreter operates by displaying a prompt and waiting for the user to enter a program name. It then executes the specified program. This process occurs in an infinite loop, making it a fundamental component of the operating system. The shell provides a user interface for interacting with the operating system.
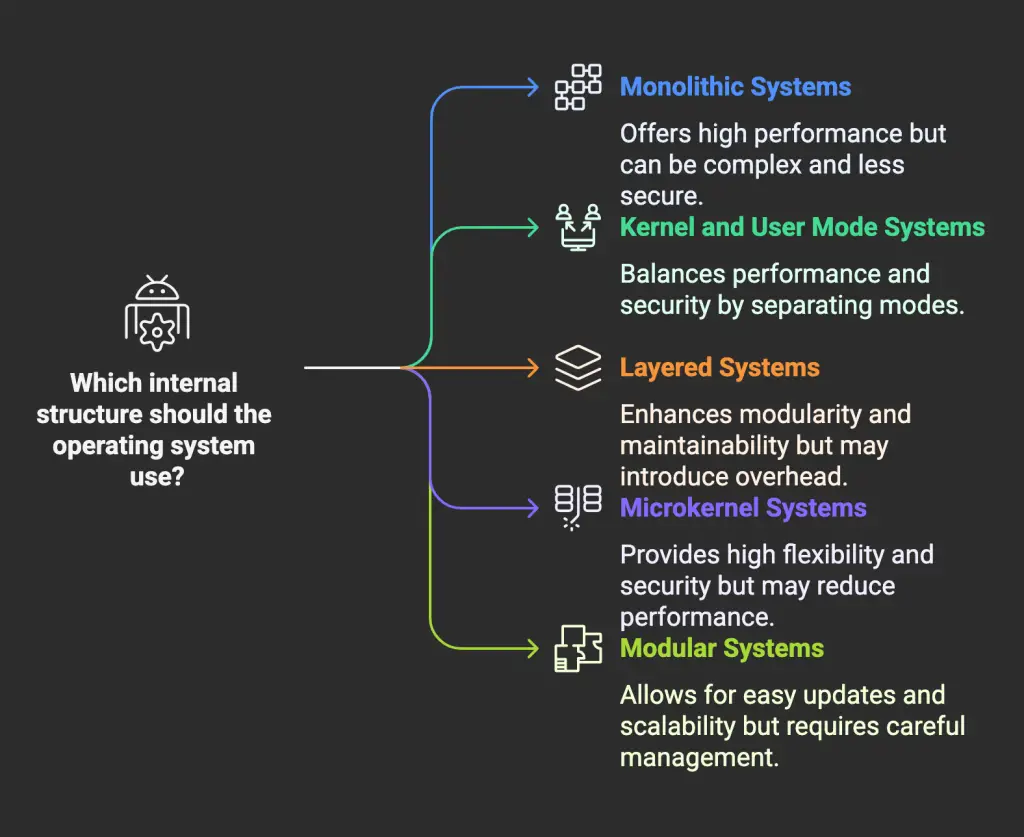
4. Internal Structure of an Operating System
Having examined an operating system from an external perspective (the user and programmer interface), let’s explore its internal workings. Different operating system designs have different internal structures.
4.1 Monolithic Systems
Andrew Tanenbaum describes a monolithic system, also known as a self-contained system, as an operating system composed of procedures that can call any other procedure at any time. This is the most common, and often least structured, way operating systems are organized. In a monolithic kernel, all operating system services run in kernel space.
Read: How to Recover Deleted or Corrupted Files on Linux with These 14 Amazing Tools
To create the object code for the operating system, all procedures or files containing them must be compiled, and then linked together using a linker. In a monolithic system, there is no information hiding – each procedure is visible to all others. This contrasts with modular structures, where information is confined to specific modules, and access is through defined entry points. Monolithic kernels can be large and complex.
MS-DOS is an example of a monolithic system.
4.2 Kernel and User Mode Systems
Many operating systems employ two modes: kernel mode and user mode. The operating system starts in kernel mode, allowing it to initialize devices and set up system call service routines. It then transitions to user mode. In user mode, direct access to peripherals is restricted; system calls must be used to access system-provided functionality. The kernel receives the system call, verifies its validity and access rights, executes it, and then returns to user mode. Only recompiling the kernel can switch back to kernel mode; even the superuser operates in user mode. Kernel mode and user mode provide a separation of privileges for security.
Examples of such systems include Unix and Windows (since Windows 95). This restriction limits what can be directly programmed on these systems. System calls provide a controlled interface between user space and kernel space.
Modern microprocessors facilitate the implementation of these systems. For instance, Intel microprocessors since the 80286 feature a protected mode with hardware checks and multiple privilege levels, rather than relying solely on software rules for switching between levels.
4.3 Layered Systems
Early systems were two-layered, but they can become more complex, with each layer building upon the one below it. The THE system, developed by Dijkstra and his students at Technische Hogeschool Eindhoven in the Netherlands, was one of the first to utilize this approach. Multics, which influenced Unix, was also a layered system. Minix, the operating system that inspired Linux and was designed by Tanenbaum, is a four-layered system. Layered operating systems provide a structured approach to OS design.
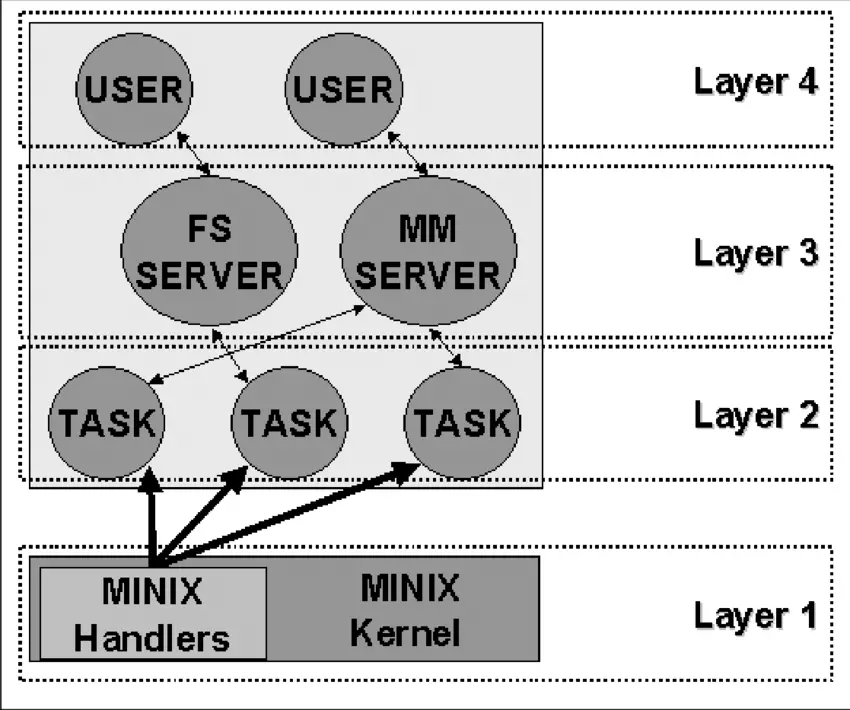
Source: ResearchGate
The lowest layer, Layer 1, is responsible for handling interruptions and traps and providing a model of separate processes communicating via messages to the higher layers. This layer has two primary functions: handling interruptions and traps, and managing the message system. The interruption handling is written in assembly language, while the other functions, including the higher layers, are written in C. Interrupt handlers are crucial for responding to hardware events.
Layer 2 contains the device drivers, one for each device (e.g., disks, clocks, terminals), and a special task called the system task. All tasks in Layer 2 and the code in Layer 1 constitute a single binary program called the kernel. Although the Layer 2 tasks are part of the same object program, they are independent and communicate via messages. They are grouped into a single binary for ease of use on two-mode machines.
Layer 3 houses the two managers that provide services to user processes. The Memory Manager (MM) manages all Minix system calls related to memory, such as fork(), exec(), and brk(). The File System (FS) handles file system calls like read(), mount(), and chdir().
Finally, Layer 4 contains all user processes, such as command interpreters, text editors, compilers, and user-written programs.
The layering concept influences Linux, although it officially recognizes only two modes: kernel and user. While not strictly layered, Linux incorporates modularity for flexibility.
4.4 Microkernel Systems
Microkernel-based operating systems are streamlined to include only a minimal set of essential functions, such as basic synchronization tools, a basic task manager, and inter-process communication mechanisms. System processes run on top of the microkernel to handle other operating system functions, like memory management, device drivers, system calls, etc. Microkernels aim to minimize the amount of code running in kernel mode.
Amoeba, Tanenbaum’s operating system, was an early example of a microkernel system.
Despite their theoretical advantages, microkernel systems have often proven slower than monolithic systems due to the overhead of message passing between different OS layers. Inter-process communication (IPC) is a key performance factor in microkernel systems.
However, microkernels offer potential benefits over monolithic systems. Designing for a microkernel necessitates a modular approach, as each layer is essentially an independent program that must interact with others through well-defined software interfaces. Microkernel-based systems are also generally easier to port to different hardware platforms, as hardware-dependent components are typically confined to the microkernel’s code. Finally, microkernel systems often utilize RAM more efficiently than monolithic systems.
4.5 Modular Systems
A module is an object file that can be dynamically linked to or unlinked from the kernel during runtime. This code typically includes a set of functions that implement tasks such as file system management or device driver functionality. Unlike layers in a microkernel system, a module does not execute in its own process. Instead, it operates in kernel mode, serving the current process, similar to any other function statically linked to the kernel. Linux uses loadable kernel modules (LKMs) to extend kernel functionality dynamically.
Modules provide a powerful kernel feature, offering many of the advantages of a microkernel without the performance penalty. Some benefits of modules include:
- Modular Approach: Because each module can be dynamically linked and unlinked, programmers must create well-defined software interfaces to access the data structures managed by the modules. This promotes easier development of new modules.
- Hardware Independence: A module does not depend on a specific hardware platform, as long as it adheres to well-defined hardware characteristics. A disk driver based on SCSI will function on an IBM-compatible computer as well as on an Alpha.
- Efficient Memory Usage: Modules can be loaded into the kernel when needed and unloaded when not, potentially automatically by the kernel, transparently to the user.
- No Performance Degradation: Once a module is loaded into the kernel, its code is equivalent to statically linked code, eliminating the need for message passing when using the module’s functions. There is a minor performance cost associated with loading and unloading modules, but it is comparable to the overhead of creating and destroying processes in a microkernel system.
Read: How to run a command without having to wait in Linux/Ubuntu
5. Implementation
5.1 System Calls
The interface between the operating system and user programs is defined by a set of “special commands” provided by the OS, known as system calls. These system calls create, utilize, and destroy various software objects managed by the OS, such as processes and files. System calls are the fundamental way user programs interact with the Linux kernel.
5.2 Signals
Processes operate independently, creating the illusion of parallelism, but sometimes information needs to be communicated to a process. Signals serve this purpose. They can be thought of as software interrupts. Signals are used for inter-process communication and event notification in Linux.
For example, in message passing, the recipient needs to acknowledge receipt of a message segment promptly to prevent loss. The segment is retransmitted if an acknowledgment is not received within a specified time. To implement this, a process can be used: it sends a message segment, requests the OS to notify it after a certain time, checks for an acknowledgment, and resends the segment if no acknowledgment is received.
When the OS sends a signal to a process, the process temporarily suspends its current operation, saves its state, and executes a specific signal handling routine. After the signal is handled, the process resumes execution from where it was interrupted. Signal handlers allow processes to respond to specific events asynchronously.
Conclusion
In summary, this article has explored the architecture of the Linux operating system. The operating system performs three core functions: program loading, acting as a virtual machine, and resource management. It is also characterized by multitasking and multi-user capabilities. The external architecture of Linux comprises components such as the kernel, task manager, memory manager, file manager, device manager, operating system loader, and command interpreter. The internal structure can vary from monolithic systems to microkernel systems. Operating system implementation is achieved through system calls and signals. Understanding how the different components of the Linux operating system interact is essential for anyone seeking a deeper understanding of computer systems, system administration, or software development on the Linux platform.
Frequently Asked Questions (FAQ)
I. General Overview and Motivation:
- Q: Why should I learn about the Linux operating system architecture?
- Understanding the architecture helps you grasp operating system design principles, potentially contribute to kernel development, and gain insights into how Linux manages resources and executes programs. It also provides a deeper appreciation for how your computer works.
- Q: What are the main goals of this article?
- The primary goals are to provide a comprehensive overview of the Linux operating system architecture for beginners, focusing on understanding OS design principles and how the system works internally.
- Q: What’s special about Linux, in comparison to the other operating systems?
- A significant advantage of Linux-based operating systems is their open-source nature. This allows you to not only learn about the system’s core principles but also observe how its features are implemented and even modify them.
II. Core Functions of an Operating System:
- Q: What are the three primary functions of any operating system?
- Program Loading and Execution: Managing how programs are loaded into memory and executed sequentially.
- Virtual Machine: Creating an abstract, simplified view of the hardware for programmers (e.g., presenting a file system instead of raw disk sectors).
- Resource Manager: Managing and allocating system resources (CPU, memory, peripherals) fairly among different programs and users.
- Q: How did early microcomputers handle program loading without an operating system?
- Early microcomputers often had a single program (like a BASIC interpreter) stored in ROM. Later, floppy drives allowed users to load different programs, but switching often required a system restart.
- Q: How does an operating system make hardware easier to use for programmers?
- The OS provides an abstraction layer (the “virtual machine”). Instead of dealing with the complex, low-level details of hardware (like an IDE controller), programmers can use a simplified API (e.g., opening, reading, and writing files).
- Q: How does the operating system prevent multiple programs from interfering with each other when using shared resources (like a printer)?
- The OS manages shared resources by techniques like buffering. For example, print jobs are spooled to a file and then printed sequentially, preventing output from different programs from being mixed together.
III. Characteristics of Operating Systems (Multitasking and Multi-user):
- Q: What is “multitasking,” and how does it work in Linux?
- Multitasking allows multiple programs (processes) to appear to run simultaneously. Linux uses “timesharing,” where the CPU rapidly switches between processes, giving each a small slice of time.
- Q: What’s the difference between a “program” and a “process”?
- A program is the code itself (e.g., a text editor). A process is a running instance of that program. You can have multiple processes of the same program running at the same time.
- Q: What are “environment variables” in the context of a process?
- Environment variables define the context in which a process runs, including information like open files, the current program counter value, and other settings. This information is saved when a process is interrupted, allowing it to resume correctly later.
- Q: What does “pseudo-parallelism” mean?
- Pseudo-parallelism is the illusion of simultaneous execution created by timesharing. The CPU switches between processes so quickly that it appears they are running at the same time, even though only one process is truly active at any given instant.
- Q: Why is it important that processes don’t rely on specific time frames in a multitasking system?
- Because the processor switches between processes, the execution speed of any single process is not constant. Relying on precise timing can lead to errors (like missing data from a floppy drive). Timers and scheduling policies are used for time-critical operations.
- Q: What does it mean for an operating system to be “multi-user”?
- A multi-user OS allows multiple users to run applications concurrently and independently, without interfering with each other. Linux is designed as a multi-user system from the ground up.
- Q: What mechanisms are essential for a multi-user operating system?
- Multi-user systems require:
- Authentication: Verifying user identities (e.g., username/password).
- Protection: Preventing users or programs from interfering with each other or accessing unauthorized data.
- Accounting: Tracking resource usage by each user.
- Multi-user systems require:
- Q: What are User IDs (UIDs) and Group IDs (GIDs)?
- UIDs uniquely identify each user. GIDs identify groups of users, allowing for controlled sharing of resources (like files).
- Q: Who is the “superuser” (or root) in Linux?
- The superuser (root) has complete control over the system and can perform any operation, including managing users and system resources.
IV. External Architecture (Components of an Operating System):
- Q: What is the “kernel” of an operating system?
- The kernel is the core of the OS, containing the most critical routines for system operation. It’s loaded into memory during startup.
- Q: What are the main components of the Linux kernel?
- The kernel typically includes:
- Task Manager (Scheduler): Allocates CPU time to processes.
- Memory Manager: Manages memory allocation and deallocation.
- File Manager: Provides a hierarchical file system structure.
- Device Manager: Handles communication with hardware devices.
- Operating System Loader: Loads the OS into memory during startup.
- Command Interpreter (Shell): Provides a user interface for interacting with the OS.
- The kernel typically includes:
- Q: What is the function of the Memory Manager?
- The memory manager is responsible for tracking memory usage. It monitors which memory regions are occupied and which are free, allocates memory to processes as needed, reclaims memory when a process terminates, and manages data transfer (swapping or paging) between main memory and disk when main memory cannot accommodate all processes.
- Q: What is the function of the File Manager?
- As previously mentioned, a key function of the operating system is to abstract the complexities of disks and other I/O devices, providing programmers with a simplified model. This is achieved through the concept of a file.
- Q: What is the function of the Device Manager?
- Managing computer input and output (I/O) devices is a primary responsibility of an operating system. It sends commands to peripherals, handles interruptions, and manages any errors that may occur.
- Q: What is the function of the Operating System Loader?
- The operating system loader and the command interpreter are essential components of a computer’s operating system. When a computer is powered on, the BIOS software is loaded into RAM and initializes the devices. The OS pre-loader then takes over and loads the operating system onto the computer.
- Q: What is a “shell” (command interpreter)?
- The shell is a program that provides a text-based interface for users to interact with the operating system. It displays a prompt, accepts commands, and executes programs.
V. Internal Structure of Operating Systems:
- Q: What is a “monolithic” operating system?
- In a monolithic system, all OS procedures can call any other procedure at any time. This is a common but often less structured approach. MS-DOS is an example.
- Q: What is the difference between “kernel mode” and “user mode”?
- Kernel mode has full access to hardware and system resources. User mode has restricted access, and programs must use “system calls” to request services from the kernel. This separation enhances security.
- Q: What is a “layered” operating system?
- A layered system organizes the OS into a hierarchy of layers, each building upon the layer below it. This promotes modularity and structure. Minix is an example.
- Q: What is a “microkernel” operating system?
- A microkernel system minimizes the code running in kernel mode, including only essential functions like basic task management and inter-process communication. Other OS services run as separate processes. Amoeba is an example.
- Q: What are the potential advantages and disadvantages of a microkernel?
- Advantages: Modularity, hardware independence, potentially better RAM usage. Disadvantages: Can be slower than monolithic systems due to the overhead of message passing between processes.
- Q: What are “loadable kernel modules” (LKMs) in Linux?
- LKMs are object files that can be dynamically linked to or unlinked from the kernel at runtime. They provide a flexible way to extend kernel functionality (e.g., adding support for new hardware) without recompiling the entire kernel.
- Q: What are some benefits of using Modules?
- Modular Approach
- Hardware Independence
- Efficient Memory Usage
- Q: What are “system calls”?
- System calls are the interface between user programs and the operating system kernel. They are special commands that allow programs to request services from the OS (e.g., creating a file, allocating memory).
- Q: What are “signals” in Linux?
- Signals are software interrupts used for inter-process communication. They allow the OS or other processes to notify a process of an event, causing it to interrupt its current operation and execute a signal handler.
If you like the content, we would appreciate your support by buying us a coffee. Thank you so much for your visit and support.