In this article you will learn how to use the grep command on Linux along with simple examples to help you find a string or pattern within a given file.
Overview of the grep command
Simply put, grep is a powerful pattern based tool used to search text within files . It is one of the most invoked utilities on Linux or Unix. Basically, grep, which stands for ‘global regular expression print’ looks up a specific file for lines which contain a match to some given strings or words or even regular expressions and outputs the corresponding line. If grep is not installed on your system for whatever reason, you can always perform an installation using your package manager (apt-get on Debian/Ubuntu) by running the command :
sudo apt-get install grep
Read: How to copy a file to multiple directories in Linux
The grep command syntax and how to use grep
The syntax of the grep command is easy but it can get complicated as well depending on the nature of the task to be carried out. The basic grep usage syntax is as follows :
grep [GREP COMMAND OPTIONS] PATTERN [FILE…]
For example :
grep ‘single_word’ file_name. [Linux grep command]
grep ‘single_word’ first_file second_file
grep ‘first_string second_string’ file_name
command | grep ‘yourtext’’
cat one_file | grep ‘yourtext’
command option | grep ‘text’
Search files
Let’s say you want to search for a given word in one specific file. In the example below, we want to find the line which contains the word ‘domain’ in a file called index.htm in the current directory . This can be achieved by running the grep command below :
grep ‘domain’ index.html [grep Linux command]

grep in Linux
In order to check that this a correct output, let’s see the content of the file named index.html by executing :
nano text.html
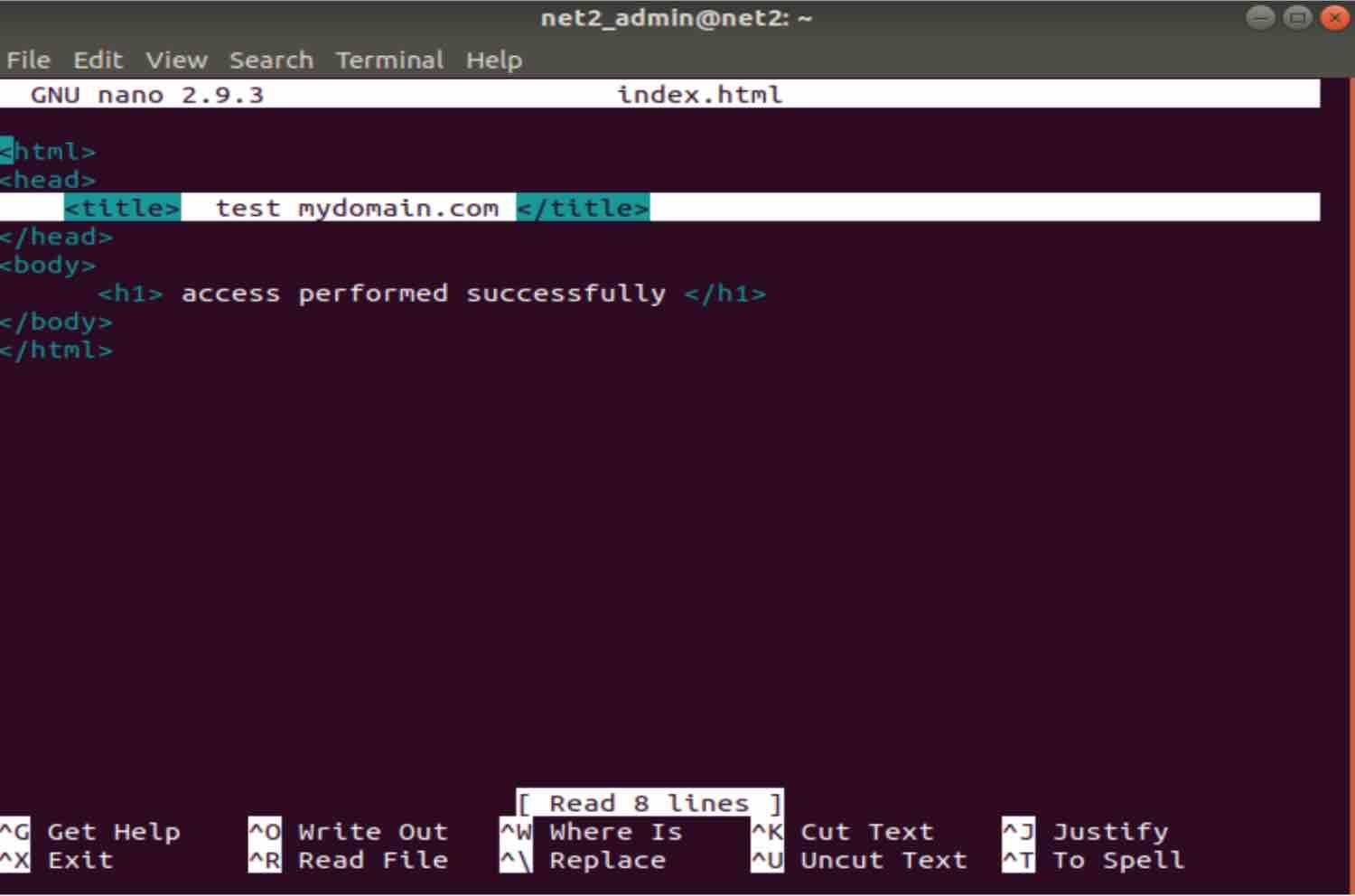
As you can see, the result returned does indeed match the highlighted line above.
Now if you invoke the same grep command above but with a small alteration which consists in changing the first letter of the word ‘domain’ to uppercase :
grep ‘Domain’ index.html

As you can see, this has returned no results because the grep command is case sensitive.
In order to ignore the word case, you simply need to add the -i switch as follows :
grep -i ‘Domain’ index.html

As a alternative to the above command, you can also use the cat command as follows giving you the same result:
cat index.html | grep -i ‘Domain’

Here the cat command prepares the content of the file ‘index.html’ before outputting it to the grep command in order for the latter to do its job of searching for the word ‘Domain’ .
In order to better understand the example above, issue the command below :
dpkg –list | grep -i ‘sql’
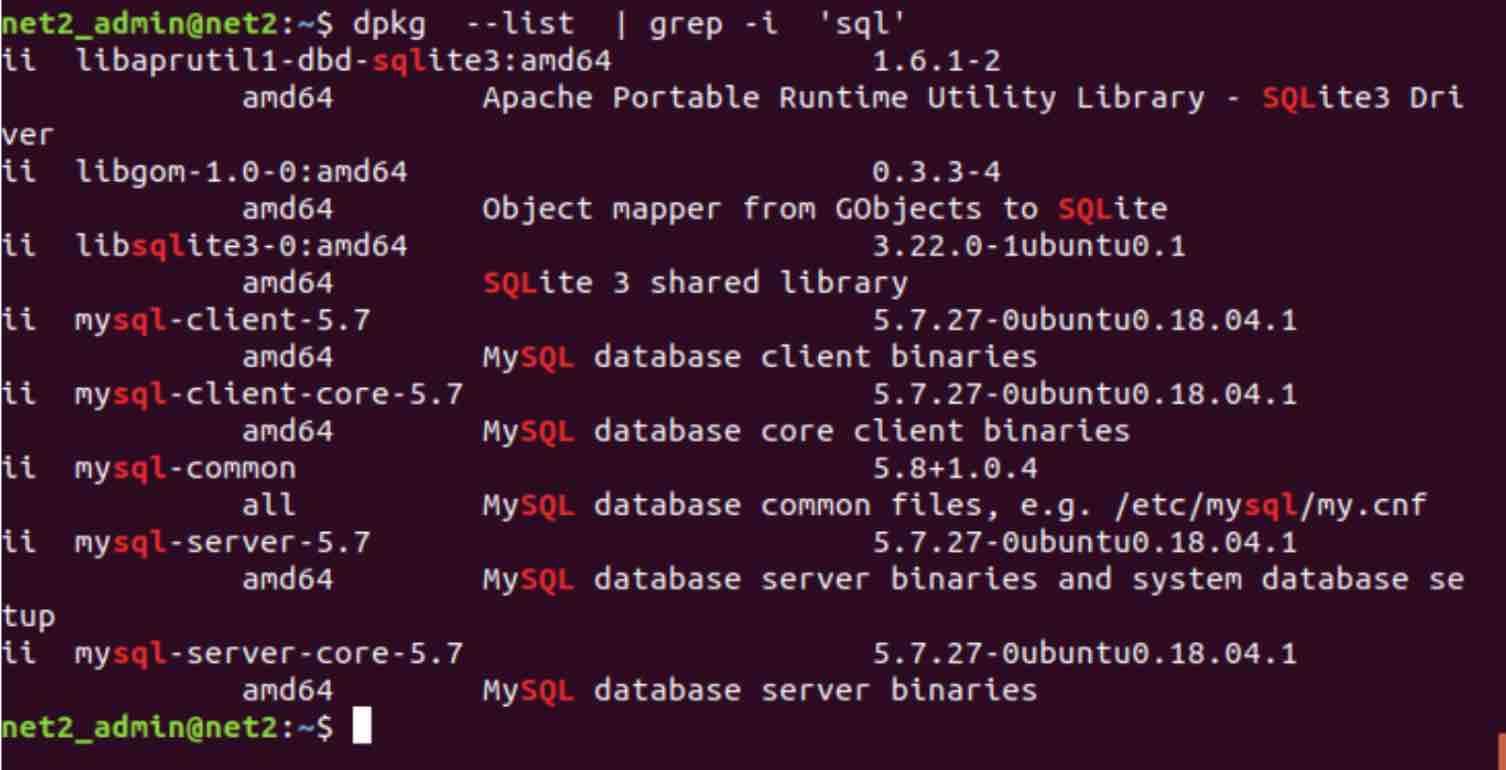
Where we executed the command ‘dpkg –list’ which will list out the installed programs. We then piped this out to the grep command in order to search for the installed packages which contain the word ‘sql’ while ignoring the case.
Read: How to compress JPEG or PNG images in Linux using the terminal
Number of lines before and after : -A -B -C options
It is also possible with grep to display the lines that are before or after the line that contains the search string.
let’s return to our test file below, i.e. ‘index.html’ :
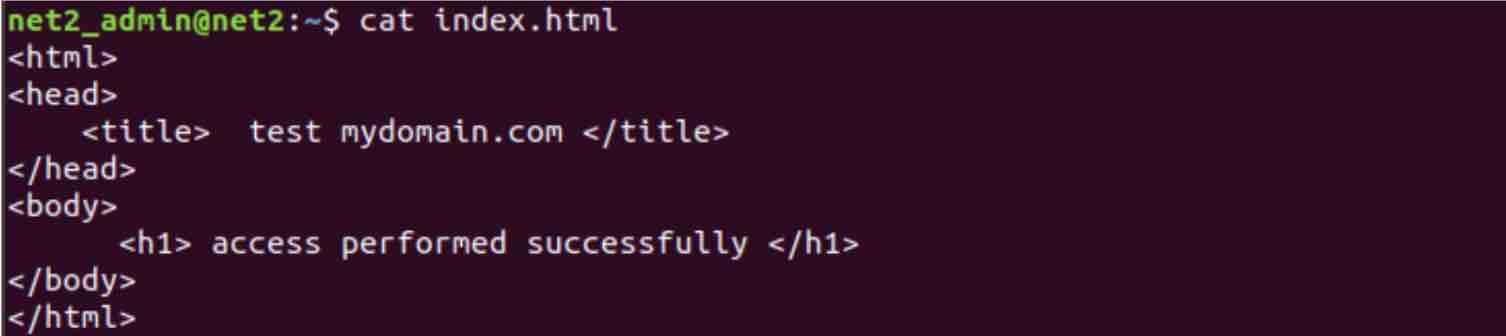
We would like to display the line that comes after the line with the word being sought, .i.e. ‘/head’ :
The command is as follows :
cat index.html | grep -B 1 “/head” ⇒ shows 1 line before
cat index.html | grep -B 2 “/head” ⇒ shows 2 lines before

Now to display the lines that come afterwards, simply issue the command below with the -A switch :
cat index.html | grep -A 1 “/head” ⇒ shows 1 line after
cat index.html | grep -A 2 “/head” ⇒ shows 2 lines after
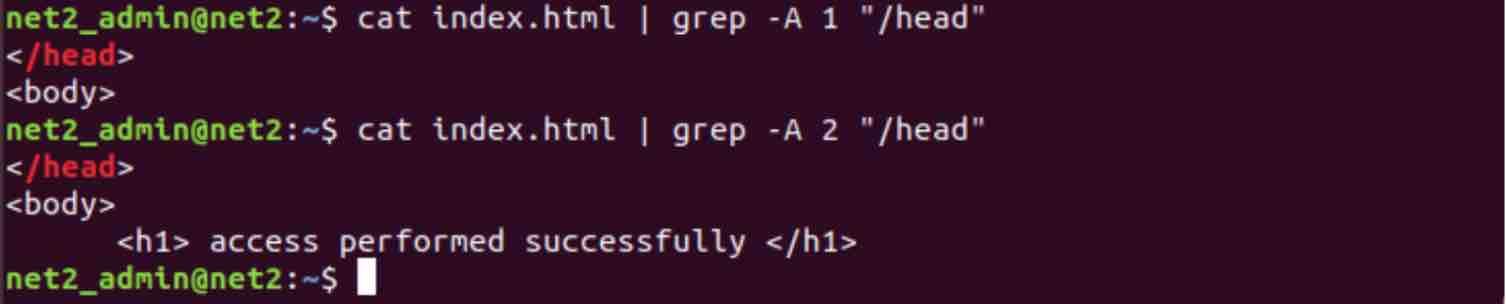
In order to display both lines, I mean that satisfy the -A criteria and the -B criteria at the same time, we use the -C option as follows :
cat index.html | grep -C 2 “/head” ⇒ shows 2 lines before and after

Invert search results : -v option
imagine you have the following html file :
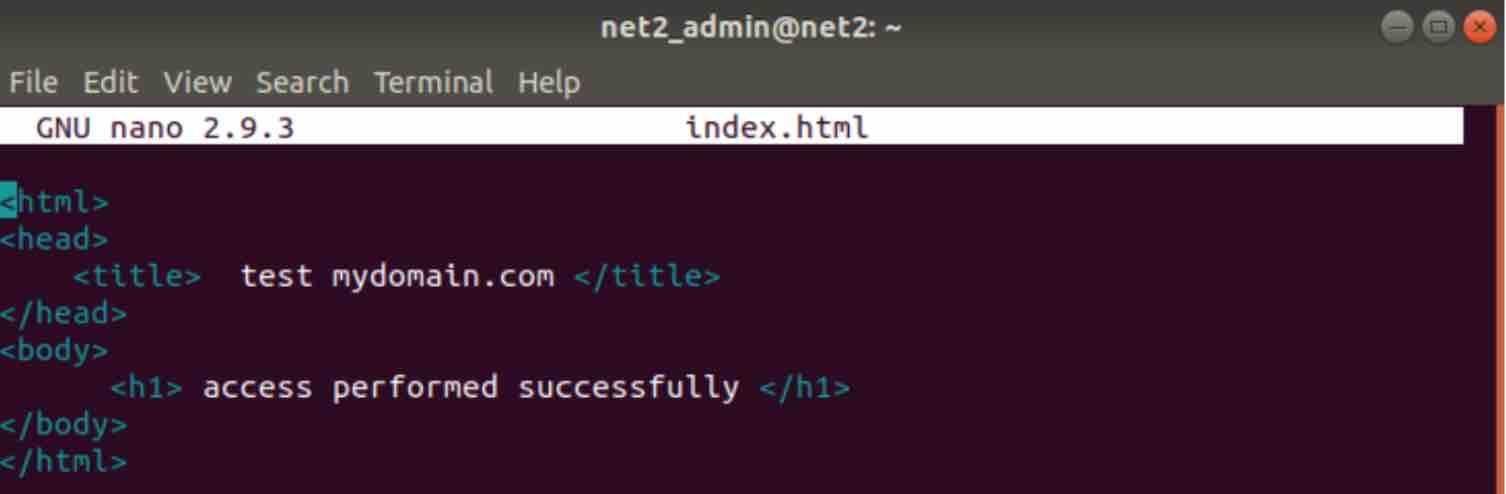
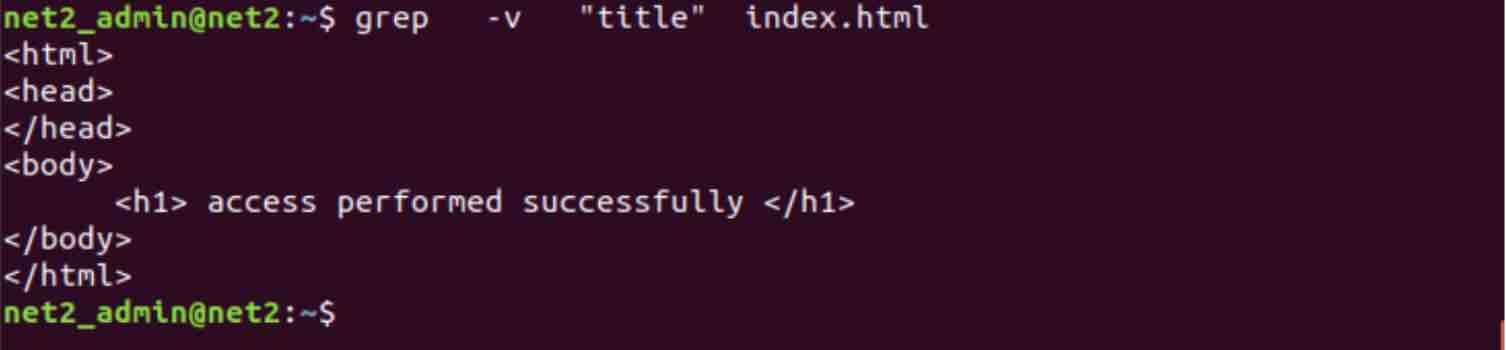
And you want to return all the lines which DO NOT contain a specific word. For instance, you want to return all the lines of the file above which do not contain the word “title”, this can be done using the -v switch as follows :
grep -v “title” index.html
use grep to search for text in a file
As you can see, the line which contains the word title is not longer returned. This is a rather powerful exclusion feature of the grep command.
Read: How to find the largest files on Linux
Find specific file extensions only
Say you have many files with different extensions in your current directory and you would like to filter out those which have the extension ‘xz’ AND whose names DO NOT contain the word “ubuntu”. This can be done via the command below :
find . –name “*.xz” | grep –vi “ubuntu”
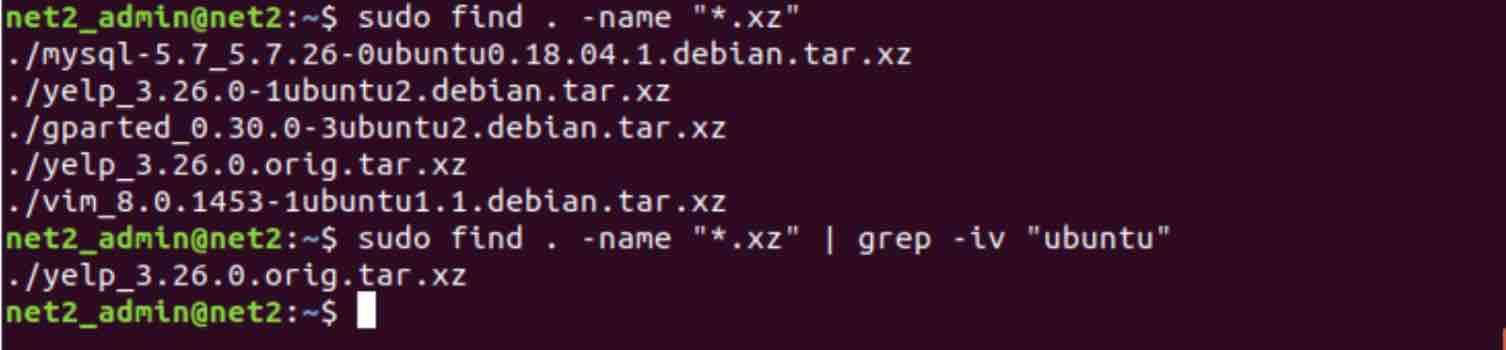
The first command above displays the list of files which end with “.xz” so that you can check the file names. The second command yielded one single entry which correspond to the file whose name does not contain ‘ubuntu’ and whose extension is as requested.
You can still search further by adding another grep, say you would like to further exclude the files which contain the word ‘mysql’. This is done via the command :
find . –name “*.xz” | grep –iv “orig” | grep –iv “mysql”
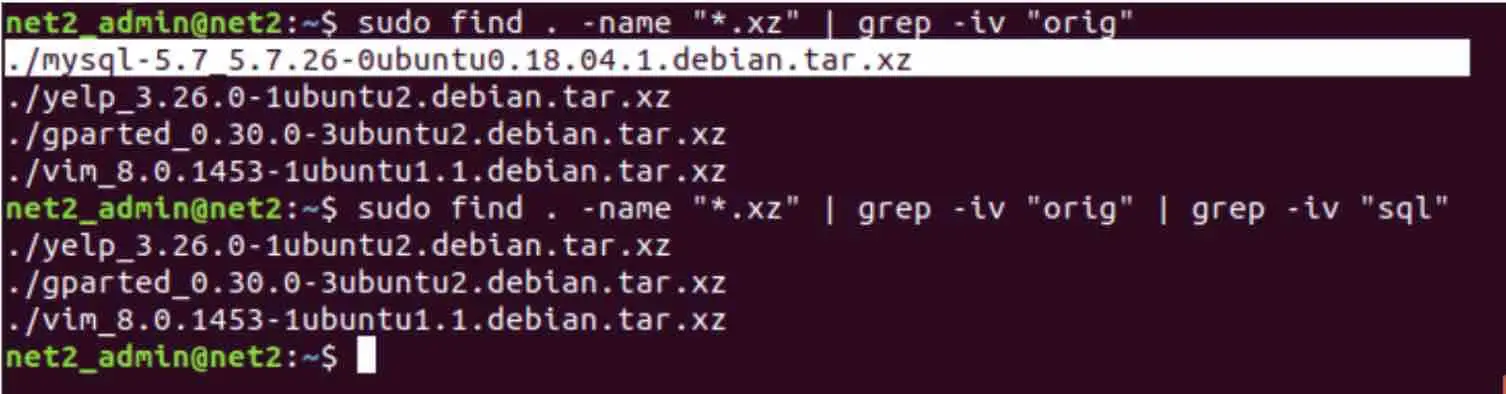
As you can see, the highlighted file above has been excluded. Note that we have slightly altered the word in the first grep, .i.e. no longer ‘ubuntu’ but ‘orig’ .
Number of occurrences: -c option
In order to display the number of matches , we use the -c switch as follows :
cat index.html | grep -c “html”
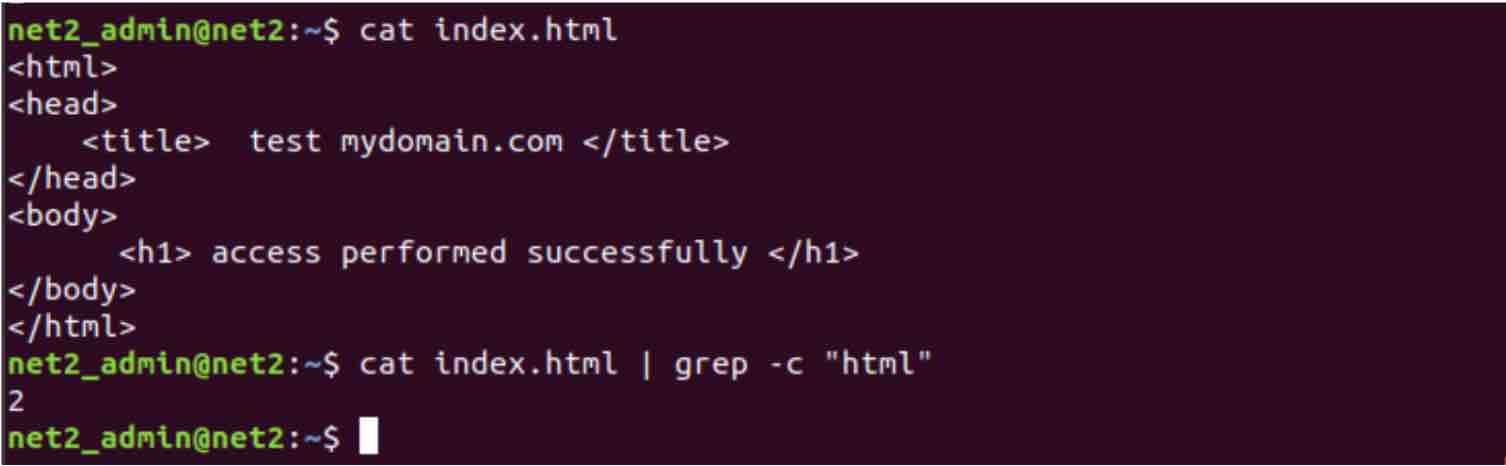
Here we see that the word “html” occurred twice in the file “index.html”
Line number display : -n option
in some situations, some files have numbered lines like for instance a computer program. It is very convenient at times to know the line number where a given string is found . this can be achieved via the -n switch below :
cat index.html | grep -n “html”
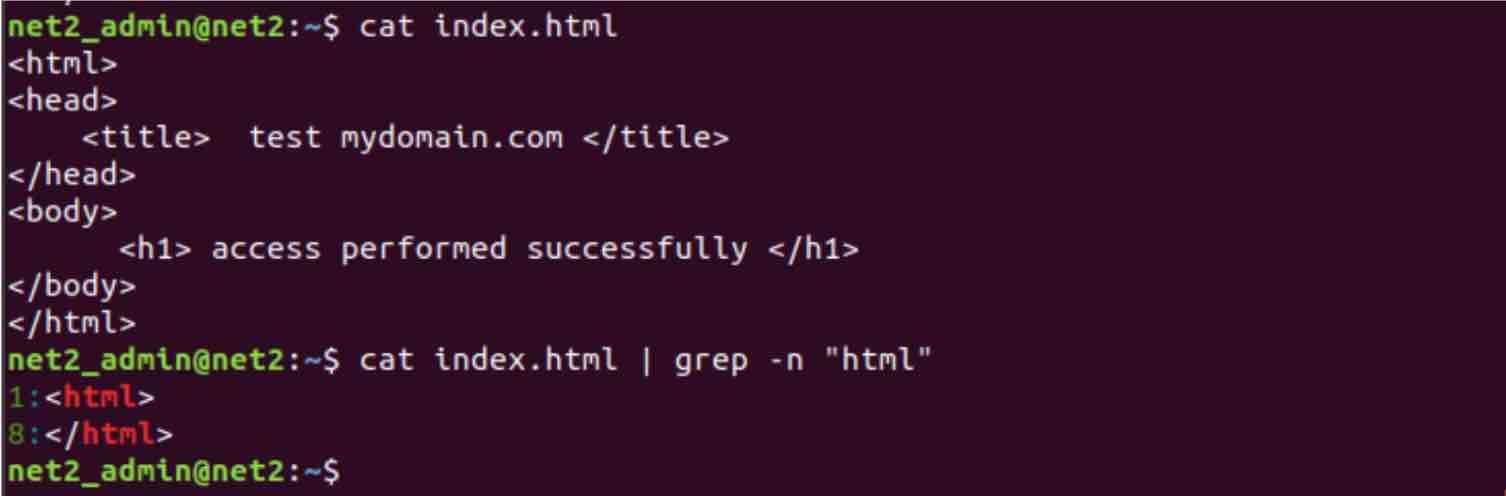
As you can see from the snapshot above, the text “html” was found at lines 1 and 8.
Recursive search: -r option
The linux grep command is extremely powerful when it comes to recursive search of files in subdirectories. For instance to search for the files which contain the word “examples” under the “/etc” folder, type in the command :
sudo grep -r “examples” /etc
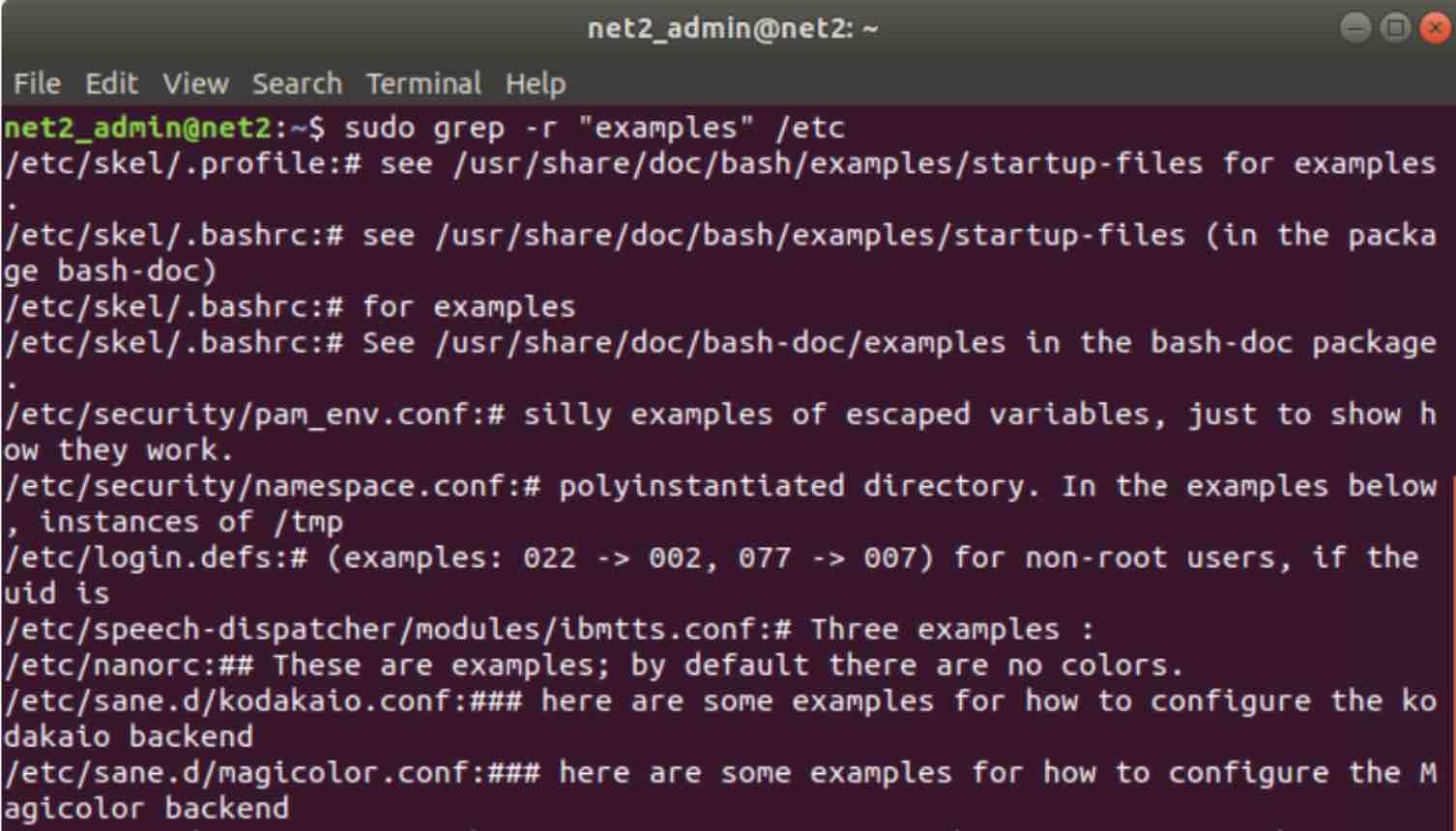
This can be read as: search all files in all sub folders of the current directory for the text string ‘examples’ and print out the file names containing this pattern.
In order to tidy up the output a little bit, we add the l switch as follows :
sudo grep -rl “examples” /etc
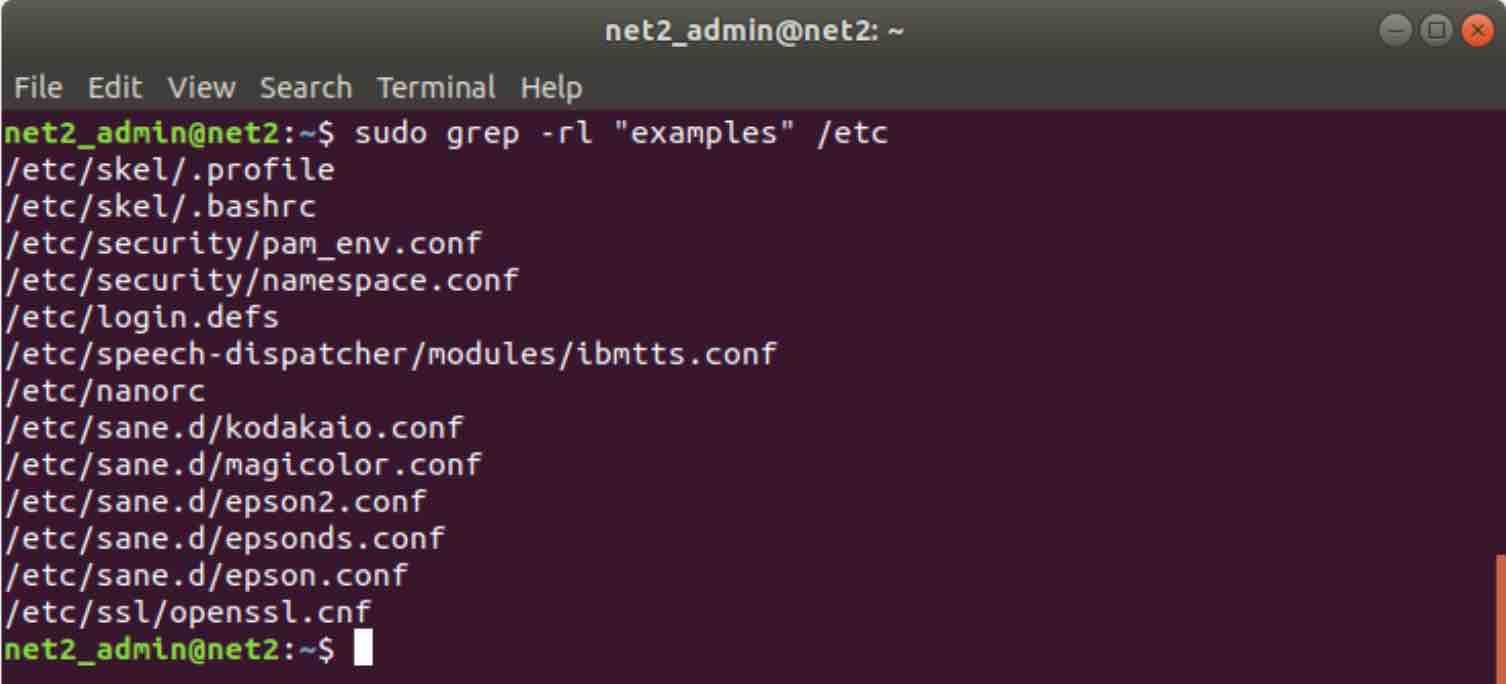
The -l option allows to only print the names of matching files without the matching lines .
If we try to test this with our “index.html” file, we first run the command “cd ..” so that our current folder becomes a subdirectory and try to search for a word“test mydomain.com” that we know it would exist in our test file.
sudo grep -r “test mydomain.com”

As you can see above, our test file has indeed been returned along with the corresponding folder.
Gzipped files string search
In order to apply grep to gzipped files, you should use its derivative command zgrep. This is used as follows:
zgrep –i “out-of-memory” /var/logs
For more on zgrep, refer to the last section below.
View output in color : –color option
The –color option allows the output to highlighted the successful match as shown below :

or as in here :

Full word search: -w option
When we searched for the word “domain”, grep will actually match ‘mydomain’ or ‘hisdomain’ and all words which contain the text “domain”. In order to force grep to select only the lines which contain matches for whole words i.e. only “domain” word, we use the -w switch as follows :
grep -w “domain” file

As you can see, the full word “domain” had no matches contrary to the word “mydomain” .
Blank characters search
In some circumstances, you would want to search for lines which start with either a Tab or a Space i.e. blank characters. In this case, you could issue the command below :
grep “^[[:blank:]]” index.html

as expected, the lines returned start with a blank.
If you would like to use a general pattern for a blank character, you just need to use the space feature as follows :
grep “^[[:space:]]” index.html

This will include the following :[tab, vertical tab, newline, space and carriage return]
Alphanumeric characters search
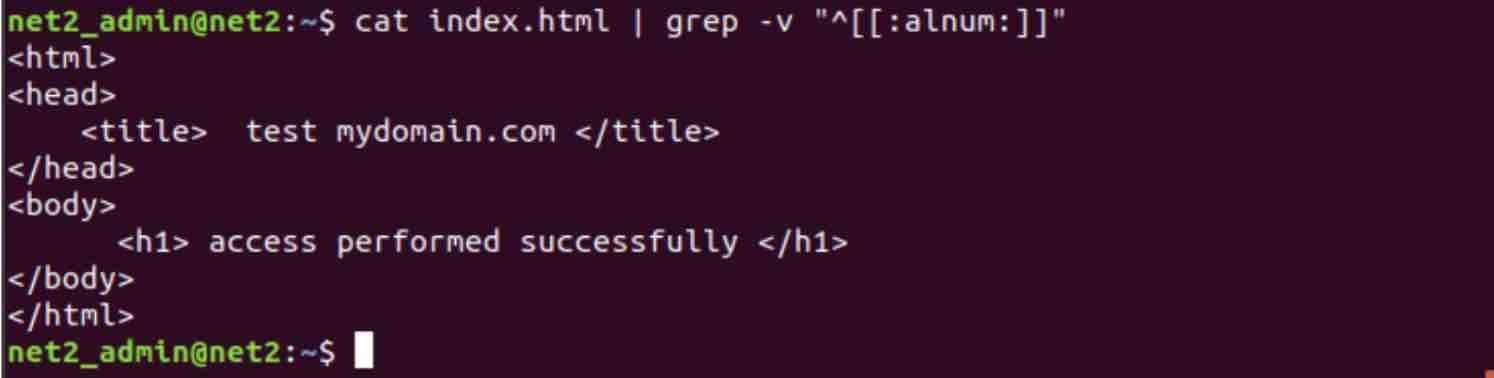
If you are looking to search for lines which start with A-Z, a-z or 0-9 , you could use the following command :
grep “^[[:alnum:]]” index.html
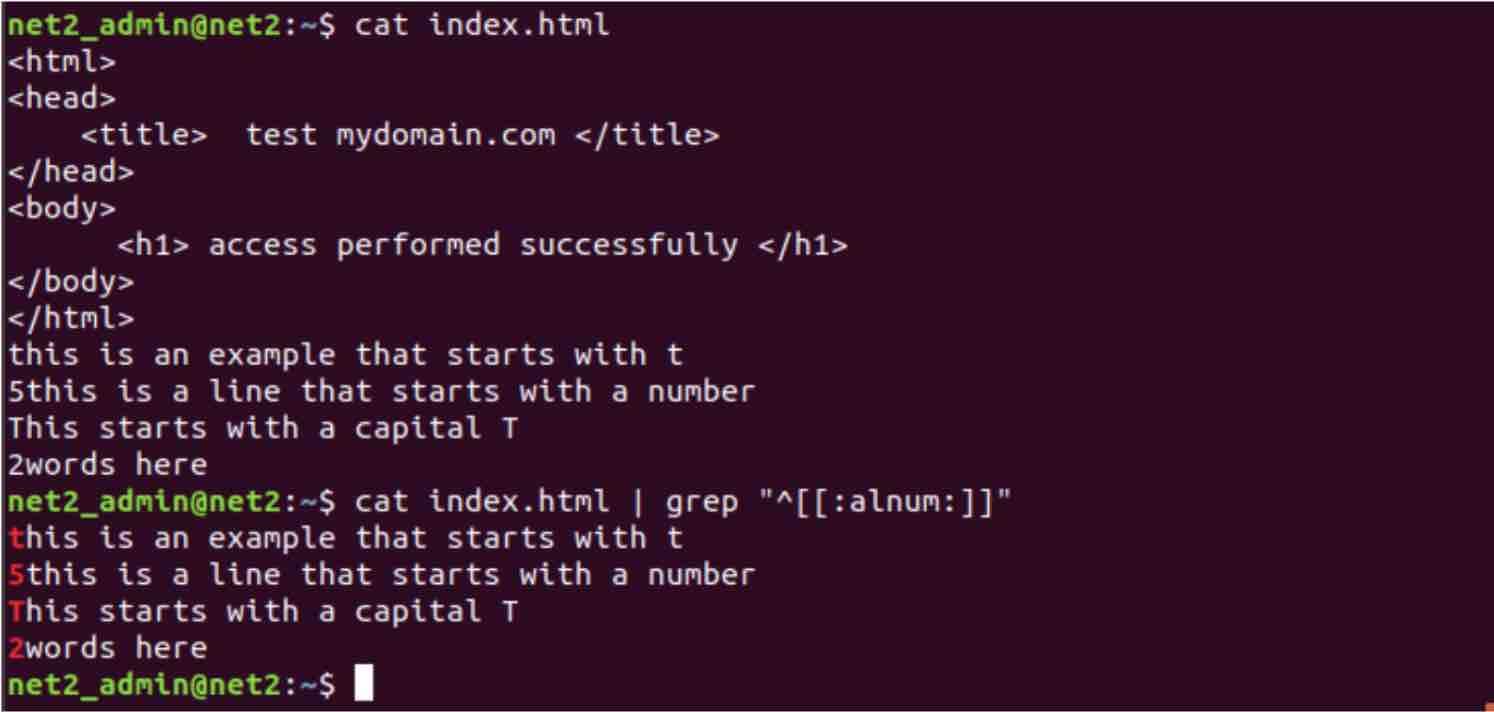
Where we have added few lines at the end of our test file “index.html”. As you can see, the returned liens are only those that start with either a character or a number. As an experiment, if you apply the -v option you will get the original output result (kinda similar to the dual space in mathematics ) :
Lowercase and Uppercase letters search
In a similar fashion, if you would like to obtain the lines which start with lowercase characters, i.e. a-z, you could use the command below :
grep “^[[:lower:]]” index.html

Similarly for uppercase, you just to replace the lowercase string above with uppercase as in the command below :

![]()
Digits search
Similarly, in order to obtain the lines which start with 0-9 only, i.e. digits, you could run the following command :
grep “^[[:digit:]]” index.html

Alpha Characters search
In case you want to search for lines which start with A-Z or a-z, i.e. only alpha characters, you could use the following command :
grep “^[[:alpha:]]” index.html

Punctuation Characters
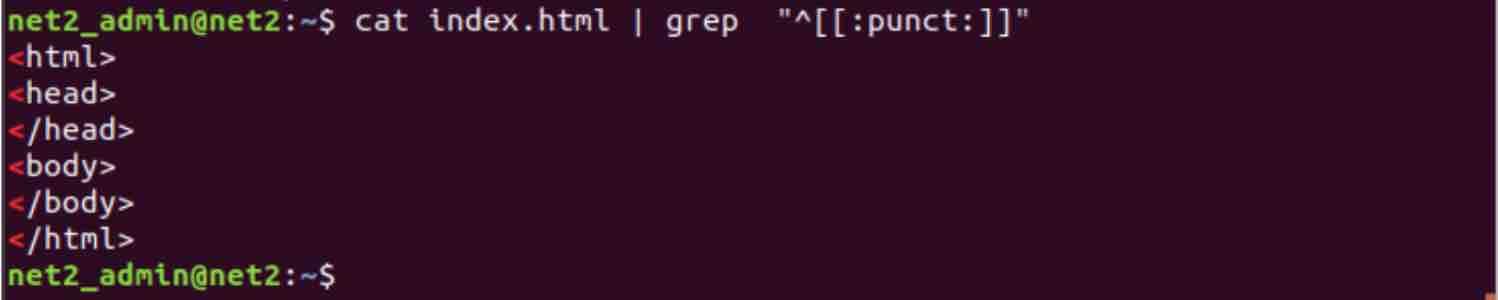
If the line being sought starts with any of the following punctuation characters, [! ” # $ % & ‘ ( ) * + , – . / : ; < = > ? @ [ \ ] ^ _ ` { | } ~. ], you could execute the command below :
grep “^[[:punct:]]” index.html
Print characters search
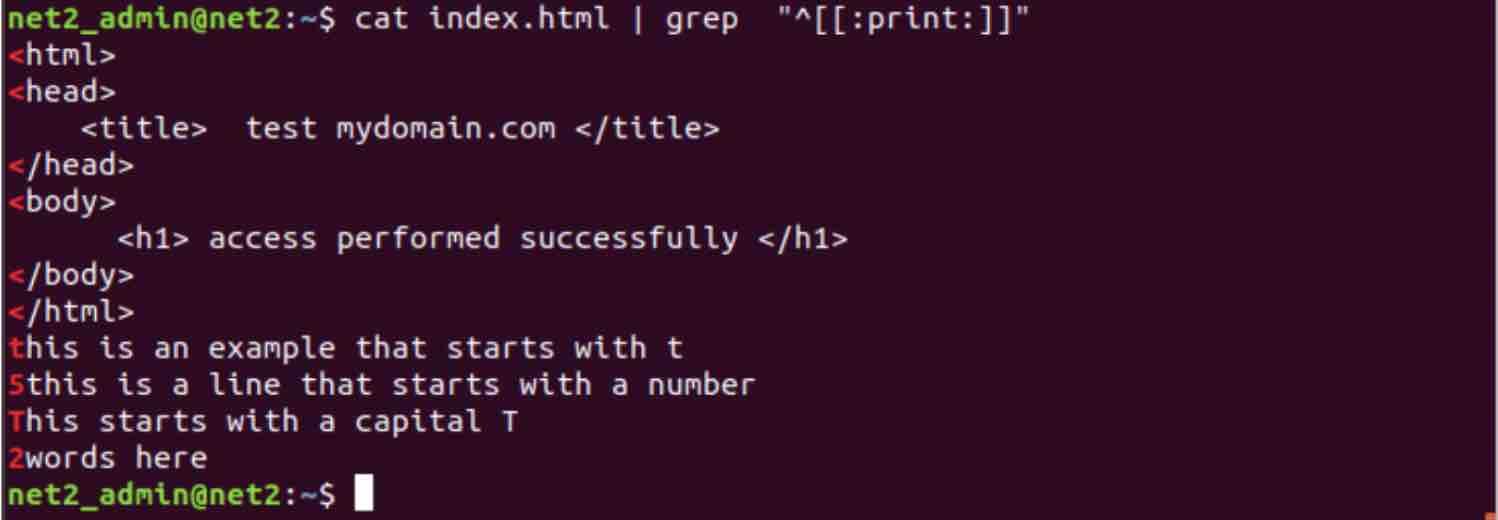
This is useful sometimes if you want to search for lines which start with punctuation, alphanumeric or space characters :
grep “^[[:print:]]” index.html
grep command derivatives
There are three variant commands that are similar to grep: zgrep, egrep and fgrep.
egrep is equivalent to running grep -E where, grep evaluates your search string as an extended regular expression (ERE).
fgrep is similar to invoking grep -F where grep evaluates your the search string as a “fixed string” .i.e. each and every character in the string is treated literally. For instance, if your search string contains an asterisk (“*”), it will be interpreted as an actual asterisk instead of a wildcard.
rgrep is equivalent to running grep -r where grep will carry out a recursive search (see corresponding section above).
If you like the content, we would appreciate your support by buying us a coffee. Thank you so much for your visit and support.