If you’re already a Linux user and maybe even a system admin for single systems, this article is for you. We’re gonna lay out the architecture of this operating system.
There are four reasons someone might be interested in understanding the design of Linux: sheer curiosity, to know how to design an OS, to contribute to Linux kernel development, or to be inspired to create a new system. Our focus is primarily on the first two reasons.
Operating systems play a crucial role in the functioning of our computers. They’re responsible for managing resources, running programs, and creating a virtual environment for all the tasks we perform on our machines. In this article, we’ll dive into the three main functions of operating systems and the various characteristics that define them. We’ll also explore the external architecture, including the various components that make up an operating system and their functions. Additionally, we’ll take a closer look at the internal structure of operating systems, including their different types and how they’re implemented. Whether you’re a tech-savvy individual or simply curious about what goes on behind the scenes, this article is sure to give you a better understanding of the world of operating systems.
One of the perks of a Linux-based OS is that the source code is public. So, not only can you learn about the system’s main principles, but you can also see how its features are implemented and even tinker with them yourself.
Read: Differences between a thread and a process
Table of Contents
1 The three main functions of an operating system
In simple terms, an operating system does three things: it runs programs in sequence, creates a virtual environment, and manages resources. Let’s dive into each of these tasks.
1.1 Loading programs
Back in the day, microcomputers didn’t come with an operating system. The early ones only had one program – an interpreter for the BASIC language stored in the ROM memory. But as cassette players and then floppy drives became more popular, things started to change. You could pop in a floppy with a different program and it would run. But if no floppy was inserted, the BASIC interpreter would take over.
For example, the Apple II required you to restart the microcomputer every time you wanted to switch programs. But as operating systems became available, things got easier. These OSs, stored on floppy disk or RAM memory, would display a prompt on the screen. You could swap out the boot disk for a disk with your desired program, and just type the program name into the command line and press enter. This allowed you to run one program, then another, without having to restart the system. So you could, say, write a document in a word processor, then run a different program to print it.
Read: How to manage permissions in Linux, guide for beginners
1.2 The operating system as a virtual machine
Managing a computer system like the IBM-PC is usually done in machine language, but this can be tough for most people to handle, especially when it comes to input and output. If every programmer had to understand how a hard drive works and all the errors that can happen when reading a block, not many programs would get written. That’s why we came up with a solution to take the complexity out of hardware for programmers. This involves adding a layer of software that manages everything for the programmer, and giving them an API that’s easier to work with.
For example, let’s say we want to program the I/O hard drive on the IBM-PC using an IDE controller.
The IDE controller has 8 main commands that consist of loading 1 to 5 bytes in its registers. These commands can read and write data, move the drive arm, format the drive, initialize, test, restore, and recalibrate the controller and drives.
The main commands are read and write, and they each need 7 parameters that are grouped into 6 bytes. These parameters tell the controller things like what sector to read or write, how many sectors to read or write, and if it should try to fix errors. After the operation is complete, the controller gives back 14 status and error fields grouped into 7 bytes.
Most programmers don’t want to deal with the technical details of programming hard drives. They just want a simple, high-level way to do it. For example, they want to think of the disk as a place with named files, and they want to be able to open a file for reading or writing, read or write the file, and then close it. The virtual machine part of an operating system hides the hardware from the programmer and gives them a simple view of the named files that can be read and written.
Read: 20 Essential Linux interview questions
1.3 The operating system as a resource manager
Computers these days have got all sorts of goodies, like processors, memories, clocks, disks, monitors, network interfaces, printers, and other knick-knacks that multiple users can access at the same time. The operating system plays traffic cop, making sure all the programs that want to use the processors, memories, and peripherals get a fair share.
Can you imagine what would happen if three programs tried to print their results on the same printer at the same time? Talk about a hot mess! The first few lines might come from program 1, then program 2, and program 3, and so on. But the operating system saves the day by sending the print results to a buffer file on the disk first. After the printing’s done, the operating system can sort through the buffer and print one file at a time. Meanwhile, another program can keep chugging along and cranking out results, not realizing they’re not making it to the printer just yet.
Read: Which Version of Windows 10 Is Right for You
2 Characteristics of an operating system
2.1 Multitasking systems
Modern operating systems let you do multiple things at once, like run a program while reading data from a disk, or show results on a terminal or printer. We call that multitasking or a multi-programmed operating system.
Process
The heart of multitasking operating systems is processes, not just programs. Sure, you can have the same program running multiple times at once, like having two windows open with the text editor “emacs” or “gv” to compare texts.
A process is a specific instance of a program that’s actually running. It’s not just the code, but it also includes the data and all the information that lets it pick up right where it left off if it gets interrupted (think of the execution stack, counter, etc.). That’s what we mean by the program environment.
And in Linux, they call a process a “task.”
Read: Processes in Linux – Guide for beginners
Timesharing
Most operating systems that let you do multiple things at once are run on a computer with just one microprocessor. Now, even though it can only handle one program at a time, the system can quickly switch between programs in just a few milliseconds, making it seem like they’re all running at the same time. That’s what we call a time-sharing system.
Some folks call this rapid switching of the processor between programs “pseudo-parallelism” to differentiate it from the real deal, where the processor and certain I/O devices are working together at the same time. That’s the kind of parallelism you get from hardware.
Abstraction of the process
It’s helpful to think of each process as having its own virtual processor, even though the real processor is actually switching between multiple processes. That’s why it’s easier to see them as a bunch of processes running in parallel, instead of the processor being divvied up between different processes. This quick switching is known as multi-programming.
Check out the graph below. It shows four processes all running at the same time. The main graph is a simplified representation of this scenario. Each of the four programs becomes its own separate process with its own flow control (meaning its own ordinal counter). In the last graph, you can see that over a decent chunk of time, all the processes have made progress, but at any given moment, only one is active.
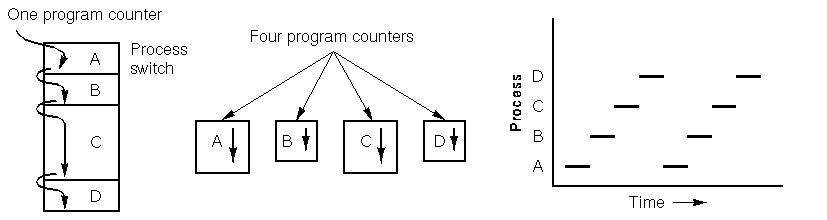
Environment variables
In simpler terms, a process isn’t just the program itself, but all the environment variables that go with it. This includes things like the files it’s working with and where the ordinal counter is located. This is important because two processes can use the same code but have different files and ordinal counters. Also, because of multitasking, the operating system may need to interrupt a process to start another. So, when this happens, the process’s information needs to be saved so it can pick up right where it left off when it’s resumed. The specific environment variables needed depend on the operating system being used and even the version of it. All this info is stored in the process descriptor.
Read: How is the path environment variable managed in Linux/Ubuntu/Debian?
Memory space of a process
In many OSes, each process gets its own dedicated memory space, separate from other processes. We refer to this as the process’s address space.
Impact on the processing of durations
Due to the fact that the processor hops from one process to another, the speed at which a process runs won’t be consistent and may change if the same process is run again. That’s why processes shouldn’t count on a specific time frame.
Take a floppy disk drive I/O process as an example. It turns on the drive’s engine, runs a loop 1000 times for the floppy to stabilize its speed, then requests to read the first record. But if the processor was busy handling another process during the loop, the I/O process may resume too late, meaning after the head has already missed the first record.
In situations where a process needs to time events with accuracy, like events that need to happen after a few milliseconds, extra precautions must be taken. That’s where timers come in handy, as we’ll see later in this article.
But for the most part, processes aren’t affected by the processor’s juggling act and the varying speeds between processes.
2.2 Multi-user systems
A multi-user system lets multiple users run their apps at the same time and without interfering with each other. “Concurrent” means the apps can run simultaneously and fight for access to resources like the processor, memory, and hard drives. “Independent” means each app can do its thing without having to worry about what the other user’s apps are up to.
Just because a system is multi-user, doesn’t mean it’s multi-tasking. For example, MS-DOS is a single-user, single-task system, while MacOS 6.1 and Windows 3.1 are single-user but multi-tasking, and Unix and Windows NT are multi-user and multi-tasking.
How it works
Multi-user systems work by giving each user their own time slot. But when it comes time to switch between apps, things can slow down and mess with the speed that users experience. It’s just the nature of the beast.
Associated mechanisms
For multi-use systems, the operating system needs to have a few things in place:
First, they gotta have an authentication process to make sure they know who’s who. Second, they need to have protection in place to stop bad programs – either accidental ones that might shut down other apps, or purposely harmful ones that might mess with other users or spy on them.
And finally, they gotta have an accounting system to keep tabs on how much of the resources each user is getting.
Read: Windows, macOS or Linux, which one to choose
Users
When you’re using a multi-user system, each user gets their own private corner of the machine, like their own slice of disk space to store files and personal emails. The operating system makes sure that each user’s private stuff stays private and no one else can access it. The system also has to prevent any user from using it to invade another user’s private space.
Every user has a unique ID, known as the User ID or UID, and only a select few people are usually allowed to use the system. When someone wants to start a session, the operating system will ask for a username and password. If the information isn’t correct, the user won’t be able to access the system.
Read: How to create a Sudo user on Ubuntu
User group
In a multi-user setup, each user can be part of one or multiple groups for easier sharing. A group is identified by a unique number, known as a Group ID (GID). For instance, a file is only associated with one group, and on Unix, access to it can be restricted to the owner, the group, or no one else.
Superuser
A multi-user operating system also has a special user called the superuser or administrator. This user has to log in as the superuser to manage other users and handle system maintenance tasks like backups and software updates. The superuser has more power than regular users and can do almost anything, except for accessing certain I/O ports not provided by the kernel. Unlike other users, protection mechanisms do not apply to the superuser.
Read: How to fix high memory usage in Linux
3 External architecture of an operating system
3.1 Kernel and utilities
The operating system has a bunch of routines, with the most important ones being part of the kernel. The kernel is loaded into your computer’s memory when the system starts up and it’s got all the important procedures needed to keep the system running smoothly. The other, less important routines are called utilities.
The kernel of an operating system has four main parts: the task manager (also known as the process manager), the memory manager, the file manager, and the I/O device manager. It’s also got two helpers: the operating system loader and the command interpreter.
3.2 The task manager
On a timeshare system, the task manager (or scheduler) is one of the most crucial parts of the operating system. It divides up time on a single processor system. Every so often, the task manager decides to stop what’s going on and start something else, either because the current process has used up all its time or it’s waiting for data from a peripheral.
Managing lots of things happening at once can be tough, so over the years, the designers of operating systems have made it easier by constantly improving how parallel activities are handled.
Some operating systems only let you run processes that can’t be stopped by the task manager, meaning it only kicks in when a process decides to give up control. But on a multi-user system, the processes have to be able to be stopped so the task manager can control them.
Read: Guide to Linux Ubuntu/Debian log files for beginners
3.3 The memory manager
Memory is a valuable resource that needs to be handled with care. By the late 80s, even the smallest computer had 10x more memory than the IBM 7094, the most powerful computer of the early 60s. However, program sizes have grown just as quickly as memory capacities.
It’s the memory manager’s job to keep track of memory usage. It needs to know which parts of memory are occupied and which are free, allocate memory to processes that need it, reclaim memory when a process ends, and manage the transfer of data (swapping or paging) between the main memory and disk when the main memory can’t handle all the processes.
3.4 The file manager
As we mentioned earlier, a crucial part of the operating system is to conceal the complexities of disks and other input/output devices and provide programmers with an easy-to-use model. This is achieved through the concept of a file.
3.5 The device manager
Handling computer input and output (I/O) devices is a top priority for an operating system. It’s responsible for sending commands to peripherals, catching interruptions, and dealing with any errors that may arise. The operating system should also make it easy for users by providing a user-friendly interface between the peripherals and the rest of the system, no matter which peripheral is being used. The I/O code plays a big role in the whole operating system.
A lot of operating systems have a layer of abstraction that allows users to do I/O without getting bogged down by hardware details. This abstraction makes each device look like a special file, so I/O devices can be treated like files. Unix is one example of an operating system that does this.
Read: Task scheduling on Linux: CRONTAB
3.6 The operating system loader
The operating system loader and the command interpreter are two crucial components of a computer’s operating system. When you turn on your computer, whether it’s a PC or Mac, the BIOS software gets loaded into RAM and initializes the devices. The OS pre-loader then takes over and loads the OS onto the computer. The design of the loader and pre-loader is vital, even though they’re not technically part of the OS.
3.7 The command interpreter
On the other hand, the command interpreter is often seen as part of the operating system, even though system programs like text editors and compilers are not. The command interpreter, also known as a shell, operates by displaying a prompt and waiting for the user to enter a program name. Then, it executes the program entered by the user. This process happens in an infinite loop, making it a fundamental component of the operating system.
4 Internal structure of an operating system
Now that we’ve taken a look at an operating system from the outside (from the perspective of the user and programmer interface), let’s dive into its inner workings.
4.1 Monolithic systems
Andrew Tanenbaum describes a monolithic system, also known as a self-contained system, as an operating system made up of procedures that can call any other procedure at any time. This is the most common and often chaotic way operating systems are organized.
Read: How to Recover Deleted or Corrupted Files on Linux with These 14 Amazing Tools
To create the object code for the operating system, you have to compile all the procedures or files that contain them, then link everything together using an editor. With a monolithic system, there’s no information hiding – each procedure is visible to all the others. This is different from modular structures, where information is confined to specific modules and there are designated points to access the modules.
An example of a monolithic system is MS-DOS.
4.2 Kernel and user mode systems
Many operating systems have two modes: kernel mode and user mode. The operating system starts up in kernel mode, which lets it initialize devices and set up system call service routines. Then, it switches to user mode. In this mode, you don’t have direct access to peripherals, you have to use system calls to access what the system provides. The kernel receives the system call, verifies it’s a legitimate request and checks for access rights, executes it, and then goes back to user mode. Only recompiling the kernel can change it back to kernel mode, even the superuser operates in user mode.
Examples of such systems include Unix and Windows (since Windows 95). This is why you can’t program everything on these systems.
Modern microprocessors make it easier to set up these systems. For example, Intel’s microprocessors since the 80286 have a protected mode with hardware checks and multiple levels of privileges, instead of just software rules to switch between levels.
4.3 Layer systems
Earlier systems were two-tiered, but they can get more complex, with each layer building on top of the one beneath it. THE system, created by Diskstra and his students at Technische Hogeschool in Eindhoven in the Netherlands, was one of the first to use this approach. Multics, which originated from Unix, was also a layered system. And Minix, the OS that inspired Linux and designed by Tanenbaum, is a four-layered system.
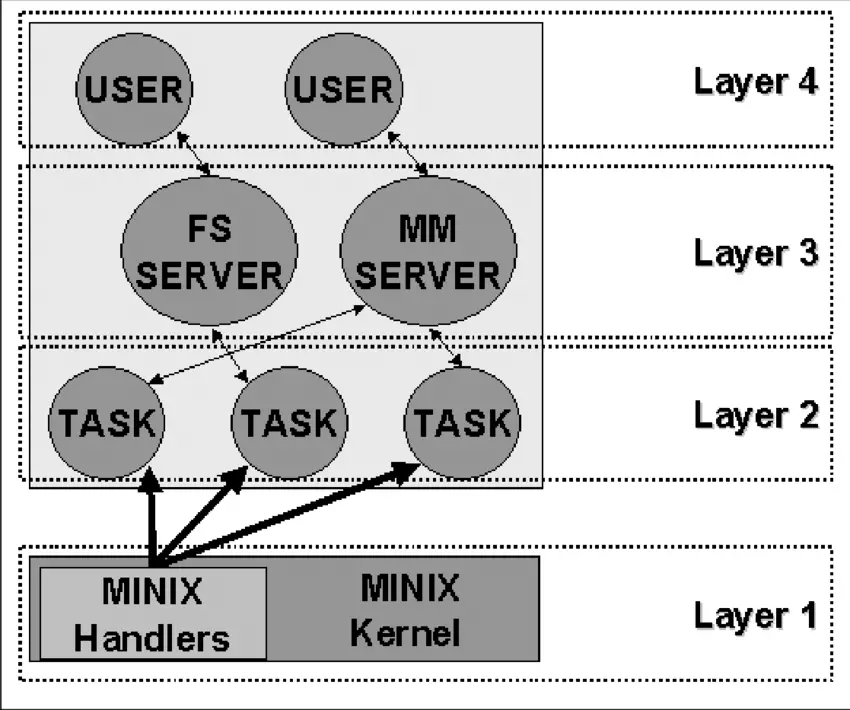
Source: ResearchGate
The lowest layer, Layer 1, is in charge of handling interruptions and traps and giving the higher layers a model made up of separate processes that talk to each other through messages. This layer has two main functions: handling interruptions and traps, and managing the message system. The interruptions part is written in assembly language while the other functions, including the higher layers, are written in C.
Layer 2 has all the device drivers, one for each device (like disks, clocks, and terminals), and also has a special task called the system task. All the tasks in Layer 2 and the code in Layer 1 make up a single binary program called the kernel. Even though the Layer 2 tasks are part of the same object program, they’re all independent and communicate by sending messages. They’re grouped together in one binary code to make it easier to use Minix on two-mode machines.
Layer 3 is where the two managers that provide services to user processes live. The Memory Manager (MM) manages all the Minix system calls related to memory, like fork(), exec(), and brk(). The File System (FS) is in charge of file system calls like read(), mount(), and chdir().
Finally, Layer 4 has all the user processes like command interpreters, text editors, compilers, and any programs written by the user.
Linux is influenced by the layering concept, although it officially only recognizes two modes: kernel and user.
4.4 Microkernel systems
Microkernel-based operating systems are stripped down to just a handful of essential functions, like a few synchronization tools, a basic task manager, and a way for processes to communicate with each other. System processes run on top of the microkernel to handle other operating system functions like memory management, device drivers, system calls, etc.
Amoeba, Tanenbaum’s operating system, was one of the pioneers in the microkernel world.
Despite its promise, microkernel systems have turned out to be slower than monolithic systems because of the overhead of passing messages between different layers of the OS.
However, microkernels do have some advantages over monolithic systems in theory. For instance, designing for a microkernel requires a modular approach, since each layer is essentially an independent program that needs to interact with other layers via a well-defined software interface. Also, microkernel-based systems are easier to port to other hardware platforms since hardware-dependent components are typically housed in the microkernel’s code. Finally, microkernel systems are often better at using RAM than monolithic systems.
4.5 Modular systems
The deal with a module is that it’s an object file that can be linked or unlinked from the kernel while it’s running. This code typically includes a set of functions that carry out tasks like running a file system or a device driver. Unlike the layers in a microkernel system, a module doesn’t run in its own process. Instead, it operates in the kernel mode and serves the current process, just like any other function that’s statically linked to the kernel.
Modules are a cool feature of the kernel because they offer many of the perks of a microkernel without sacrificing performance. Some of the benefits of modules include:
- Modular approach: because each module can be linked and unlinked while the system is running, programmers have to create clear software interfaces to access the data structures that the modules handle. This makes it easier to develop new modules.
- Hardware independence: a module doesn’t rely on any particular hardware platform, as long as it follows well-defined hardware characteristics. This means a disk driver based on SCSI will work just as well on an IBM-compatible computer as on an Alpha.
- Efficient memory usage: modules can be inserted into the kernel when they’re needed and removed when they’re not, and this can even be done automatically by the kernel, making it transparent to the user.
- No performance loss: once a module is inserted into the kernel, its code is just like any other code that’s statically linked to the kernel, so no messages need to be passed around when using the module’s functions. Of course, there’s a small performance hit when loading and removing modules, but that’s comparable to the cost of creating and destroying a process in a microkernel system.
Read: How to run a command without having to wait in Linux/Ubuntu
5 Implementation
5.1 System calls
The connection between the OS and user programs is made up of a bunch of “special commands” from the OS, which are called system calls. These system calls create, use, and get rid of different software objects that the OS manages, like processes and files.
5.2 Signals
Processes run on their own, giving the illusion of parallelism, but sometimes you need to pass info to one of them. That’s where signals come in. Think of them as software interrupts for the computer.
For example, when sending a message, it’s important that the recipient sends an “I got it” as soon as they receive part of the message, so you don’t lose it. If the “I got it” doesn’t come back within a set time, the message gets sent again. To make this happen, a process is used: it sends part of the message, asks the OS to let it know when a certain time is up, checks for the “I got it” message, and if it doesn’t get it, sends the message again.
When the OS sends a signal to a process, it temporarily stops what it’s doing, saves its current state, and runs a specific process to handle the signal. After the signal is handled, the process picks back up right where it left off before the signal came in.
Conclusion
To wrap things up, let’s recap what we learned in this article about the architecture of the Linux operating system. The operating system serves three main functions, including loading programs, serving as a virtual machine, and managing resources. The operating system is also characterized by multitasking and multi-user systems. The external architecture of Linux is made up of key components such as the kernel, task manager, memory manager, file manager, device manager, operating system loader, and command interpreter. Meanwhile, the internal structure of Linux can range from monolithic systems to microkernel systems. The implementation of the operating system is achieved through system calls and signals. Understanding the architecture of Linux is crucial for anyone looking to dive deeper into computer systems.
If you like the content, we would appreciate your support by buying us a coffee. Thank you so much for your visit and support.


